Lyria 3 Pro tops the Instrumental leaderboard and generates full songs up to three minutes with vocals and timed lyrics. MiniMax Music 2.6 builds complete tracks with singing from a style description and your lyrics. MiniMax Music 2.5+ offers the same workflow with its own generation character. All 10 models run on fal through a single SDK with pay-per-use pricing.
![10 Best Text-to-Music APIs in 2026 [Reviewed]](https://refinery.fal.media/url/https%3A%2F%2Fv3b.fal.media%2Ffiles%2Fb%2F0a9eafb8%2FwjawWn1LYYXasnPqEQ5Yo_best-text-to-music-apis-2026.jpg/tr:w-1920,q-80/wjawWn1LYYXasnPqEQ5Yo_best-text-to-music-apis-2026.webp)
I ranked and tested the 10 best text-to-music APIs in 2026 using the Artificial Analysis Instrumental Music leaderboard, with a few unranked models added at the end:
TL;DR
Lyria 3 Pro: Tops the models in this guide on the Instrumental leaderboard, as it can generate full songs up to three minutes with vocals and timed lyrics.
MiniMax Music 2.6: Builds complete tracks with singing and backing arrangement from a style description and your own lyrics.
MiniMax Music 2.5+: The same lyrics-and-style workflow as 2.6 at the same price, with its own generation character.
fal runs every text-to-music model in this guide behind one API, on its own inference engine, with pay-per-use billing.
⚠️ How the research was conducted to make this list: The way these AI models were ranked was based on my testing of the text-to-music APIs inside of fal, where I generated music, and also the Elo ratings from the Artificial Analysis Instrumental Music leaderboard, where users can anonymously rate AI models. The Elo ratings are true as of June 14th, 2026.
What is the best place to generate music from text?
fal offers the best place to generate music from text with its unified API for every model in this guide, custom-built inference engine, and pay-per-use pricing.
Running ten different music models the usual way means ten provider accounts, ten billing relationships, and ten integrations to keep alive.
On fal that collapses to one account and one integration, with the model picked by the endpoint string you pass.
The integration is a single @fal-ai/client call, and switching between models reduces to editing the endpoint string.
The same setup also reaches over 1,000 models for image, video, editing, and 3D beyond the ten covered here.
As the code path does not change between models, your team can draft on a fast, low-cost AI music model and switch to a higher-fidelity one for the final output without reworking anything.
A request looks like this:
import { fal } from "@fal-ai/client";
const result = await fal.subscribe("fal-ai/minimax-music/v2.6", {
input: {
prompt: "Warm city pop with groovy synth bass, 104 BPM.",
},
});
What are the best text-to-music APIs in 2026?
The best text-to-music APIs in 2026 are Lyria 3 Pro, MiniMax Music 2.6, and MiniMax Music 2.5+.
All three run on fal with pay-per-use pricing. Here's the full shortlist:
| AI Model | Best For | Price on fal | Elo |
|---|---|---|---|
| Lyria 3 Pro | Full-length songs with vocals and timed lyrics | $0.08 per audio | 1,118 |
| MiniMax Music 2.6 | Vocal tracks from your own lyrics and a style brief | $0.15 per audio | 1,055 |
| MiniMax Music 2.5+ | Lyrics-driven vocal tracks at a low flat rate | $0.15 per audio | 1,046 |
| Eleven Music | Section-by-section control with a composition plan | $0.80 per output audio minute | 1,028 |
| Lyria 2 | Instrumental soundscapes and short ambient cues | $0.10 per 30 seconds | 1,000 |
| Lyria 3 | Quick 30-second clips with optional vocals | $0.04 per audio | Not ranked |
| Sonilo v1.1 | Long-form tracks with exact duration control | $0.0025 per second per sample | Not ranked |
| Stable Audio 2.5 | Long instrumental pieces and sound design | $0.20 per audio | Not ranked |
| CassetteAI | High-speed drafting at the lowest cost per minute | $0.02 per output minute | Not ranked |
| ACE-Step | Open-model flexibility with tag and lyric control | $0.0002 per second | Not ranked |
I tested and provided commentary for these models with the same prompt across the board:
"A dusk-lit lo-fi soul groove at 88 BPM. A muted electric guitar and upright bass lock into a relaxed pocket while a Wurlitzer comps soft chords underneath. A single warm female vocal carries the verse, then doubles into close harmony on the hook. Mood is golden-hour, unhurried, a little wistful. Analog mix with gentle vinyl crackle and rounded low end."
If there's space for Lyrics: [verse] Streetlights flicker, the night breeze sighs / Shadows stretch as I walk alone / [chorus] Wandering, longing, where should I go.
➡️ For the instrumental-only and lyric-driven models, I adapted the prompt to fit each input format.
#1: Lyria 3 Pro
Best for: Teams that want complete, structured songs with vocals, timed lyrics, and tempo control straight from a text or image prompt.
Similar to: MiniMax Music 2.6, Lyria 2.
Lyria 3 Pro is Google's full-length music model, which can build songs up to three minutes long with vocals, lyrics, and multi-language support.
What sets it apart is timed lyric control paired with natural-language tempo direction in a single prompt.
Performance
Generated using Lyria 3 Pro on fal, an AI model from Google.
Arrangement and structure: I asked for verse-chorus movement, and the model held the form cleanly, with the chorus lifting where I wanted it rather than drifting.
Vocal quality: The female vocal hook sat well in the mix, and the lyric timing tracked the beat, though I'd push the prompt harder on emotion in a second pass.
Tempo and prompt control: It locked to the 88 BPM I requested and held the golden-hour mood.
Language and lyrics: Lyria 3 Pro covers English, German, Spanish, French, Hindi, Japanese, Korean, and Portuguese, with lyrics either generated or supplied with timing cues.
How to run Lyria 3 Pro on fal
Lyria 3 Pro is available through fal's API and playground.
Prompts work best with genre, mood, instrumentation, tempo, and vocal style spelled out, and you can pass an image URL to steer the mood from a picture.
Output lands as a 44.1 kHz MP3 up to three minutes long, with SynthID watermarking on every track.
Pricing
Lyria 3 Pro costs $0.08 per audio on fal.
falMODEL APIs
The fastest, cheapest and most reliable way to run genAI models. 1 API, 100s of models
#2: MiniMax Music 2.6
Best for: Creators who write their own lyrics and want them sung over a full backing arrangement from a short style brief.
Similar to: MiniMax Music 2.5+, Lyria 3 Pro.
MiniMax Music 2.6 turns a style description and your lyrics into a complete track with singing and instrumentation in one pass.
The style prompt and the lyrics field stay separate, so you control mood and words independently.
Performance
Generated using MiniMax Music 2.6 on fal, an AI model from MiniMax.
Vocal delivery: I fed it my own chorus lines, and the phrasing came back natural, with the vocal sitting forward in the mix the way a pop track should.
Arrangement from a brief: The short style prompt was enough to get the muted-guitar and Wurlitzer feel I described, which saved me writing a long technical brief.
Structure tags: Tags like [Verse] and [Chorus] in the lyrics field can shape the arrangement reliably.
Output control: You can set sample rate, bitrate, and format, or flip on instrumental mode to drop the vocal entirely.
How to run MiniMax Music 2.6 on fal
API access plus a browser playground both cover MiniMax Music 2.6.
You can leave lyrics empty and switch on the optimizer to have the model write them from your prompt.
Pricing
MiniMax Music 2.6 costs $0.15 per audio on fal.
#3: MiniMax Music 2.5+
Best for: Creators who want the same lyrics-driven vocal workflow as 2.6 with a different generation character at the same flat rate.
Similar to: MiniMax Music 2.6, Eleven Music.
MiniMax Music 2.5+ produces complete vocal tracks from a style brief and lyrics, with the same dual-input setup as the 2.6 release.
Each generation also carries its own sonic signature.
Performance
Generated using MiniMax Music 2.5+ on fal, an AI model from MiniMax.
Vocal character: Running the same chorus through 2.5+ gave me a slightly different vocal tone than 2.6, which is useful when one version's delivery suits a project better than the other.
Lyrics workflow: The structure-tag system behaved the same as 2.6, so moving a project between the two endpoints took no rewriting.
Audio settings: Sample rate, bitrate, and format are all adjustable per request through the audio settings.
How to run MiniMax Music 2.5+ on fal
You can run MiniMax Music 2.5+ on fal through the API or test it in the playground first.
The lyrics optimizer is available here too, generating words from the prompt when the lyrics field is left blank.
Pricing
MiniMax Music 2.5+ costs $0.15 per audio on fal.
#4: Eleven Music
Best for: Producers who want section-by-section control over a track through a structured composition plan with per-section styles and lyrics.
Similar to: Lyria 3 Pro, MiniMax Music 2.6.
Eleven Music generates a track from either a single prompt or a detailed composition plan that defines each section's styles, lyrics, and duration.
That plan-based control lets you set global styles and then shape each section on its own.
Performance
Generated using Eleven Music on fal, an AI model from ElevenLabs.
Composition plan control: Breaking the track into named sections with their own styles gave me far tighter control over where the arrangement changed than a single prompt does.
Section duration handling: Setting respect_sections_durations to true held each section to the length I planned, which mattered for cutting the track to a fixed runtime.
Instrumental switch: The force_instrumental flag guarantees a vocal-free result when you want underscore rather than a song.
Output formats: A wide range of formats is available, from standard MP3 down to PCM and Opus at various sample rates and bitrates.
How to run Eleven Music on fal
Eleven Music runs on fal via API and playground.
For quick results, pass a prompt and an optional length in milliseconds between 3,000 and 600,000.
For precise work, build a composition plan with positive and negative global styles and per-section detail, and set respect_sections_durations to keep your planned timings.
Pricing
Eleven Music costs $0.80 per output audio minute on fal, rounded up to the nearest minute, so a 30-second result bills as one minute.
#5: Lyria 2
Best for: Teams that need short instrumental soundscapes, ambient cues, and non-musical audio textures from a descriptive prompt.
Similar to: Lyria 3, Stable Audio 2.5.
Lyria 2 is Google's earlier music model, generating 30-second instrumental pieces from a detailed text prompt.
It leans toward ambient and soundscape work with negative prompting and seed control.
Performance
Generated using Lyria 2 on fal, an AI model from Google.
Soundscape quality: I stripped the vocal line out of the prompt and asked for the instrumental bed alone, and it produced a clean, layered groove that held up well as a background texture.
Negative prompting: Excluding vocals and slow tempo through the negative prompt can steer the output where you want without trial and error.
Reproducibility: The seed parameter lets you regenerate a near-identical take, which can help you when you want a variation on a result you liked.
How to run Lyria 2 on fal
Available on fal via API and playground.
You can write a descriptive prompt covering genre, mood, instrumentation, and tempo, and add a negative prompt to exclude anything you don't want.
For non-musical audio, it's possible to describe the environment or specific sound effects directly in the prompt.
Pricing
Lyria 2 costs $0.10 per 30 seconds on fal.
#6: Lyria 3
Best for: Teams that want quick 30-second clips with optional vocals and image-guided mood from Google's newer model.
Similar to: Lyria 2, Lyria 3 Pro.
Lyria 3 is Google's recent high-fidelity model, generating 30-second clips from text or image prompts with vocals and lyrics.
It pairs structural coherence with multi-language vocal support in a short-clip format.
Performance
Generated using Lyria 3 on fal, an AI model from Google.
Clip quality: For a 30-second clip, the fidelity held up well, with a clean mix and coherent structure across the short runtime.
Image guidance: Passing an image URL nudges the mood of the output toward the picture, which is a useful way to brief without writing everything out.
Language support: Lyria 3 covers English, German, Spanish, French, Hindi, Japanese, Korean, and Portuguese for vocals and lyrics.
How to run Lyria 3 on fal
Run it through the fal API or test it in the playground first.
Prompts work best with genre, mood, instrumentation, tempo, and vocal style described, and you can add a negative prompt or an image URL.
Each track carries SynthID watermarking, and output is a 44.1 kHz MP3.
Pricing
Lyria 3 costs $0.04 per audio on fal.
#7: Sonilo v1.1
Best for: Developers who need long-form tracks with exact duration control and the option to generate several samples per request.
Similar to: CassetteAI, Stable Audio 2.5.
Sonilo v1.1 generates production-ready music from a single prompt, with control over style, mood, instrumentation, and an exact output length.
Its best use case is precise duration up to 600 seconds plus multi-sample generation in one call.
Performance
Generated using Sonilo v1.1 on fal, an AI model from Sonilo.
Duration accuracy: I set a specific length, and the output matched it, which is the kind of control you want when scoring to a fixed runtime.
Multi-sample output: Requesting several samples at once returns distinct takes on the same prompt, which I think is handy for picking the best of a batch.
Output format: Tracks come back as AAC in an m4a container, one file per sample.
How to run Sonilo v1.1 on fal
Sonilo v1.1 is available through fal's API and playground.
You can set the duration in seconds up to 600, and use num_samples to generate more than one track per request.
Billing scales with both length and sample count, so a longer multi-sample request costs proportionally more.
Pricing
Sonilo v1.1 costs $0.0025 per second of output per sample on fal.
#8: Stable Audio 2.5
Best for: Sound designers who want long instrumental pieces, sound effects, and evolving textures from a text prompt.
Similar to: Lyria 2, Sonilo v1.1.
Stable Audio 2.5 from Stability AI generates music and sound effects from a prompt, with a default length long enough for full instrumental pieces.
It exposes inference steps and guidance scale for direct control over how closely the output follows the prompt.
Performance
Generated using Stable Audio 2.5 on fal, an AI model from Stability AI.
Long-form generation: The default duration runs long enough for a complete instrumental piece in one pass rather than a short loop.
Prompt adherence control: Raising the guidance scale can pull the output closer to your prompt, while lowering it gives the model more room to wander, which is what I did.
Output and reproducibility: Output is WAV, with a seed returned on every generation so you can reproduce a take.
How to run Stable Audio 2.5 on fal
API and playground are both available for Stable Audio 2.5 on fal.
The main controls are seconds_total for length, num_inference_steps for detail, and guidance_scale for how strictly the output tracks the prompt.
A returned seed lets you regenerate or vary a result you want to keep.
Pricing
Stable Audio 2.5 costs $0.20 per audio on fal.
#9: CassetteAI
Best for: Teams that want the lowest cost per minute and very fast drafting for high-volume iteration.
Similar to: Sonilo v1.1, ACE-Step.
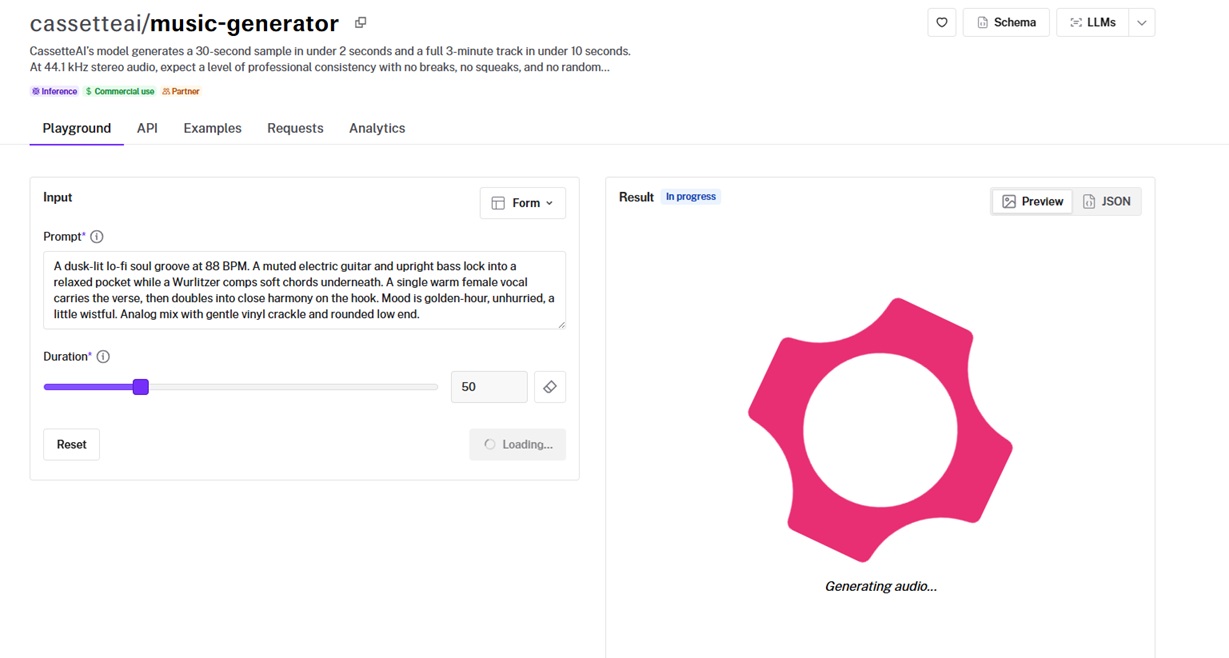
CassetteAI generates 44.1 kHz stereo music from a prompt, which is built around speed and consistency across a track.
I noticed that its generation time was faster than the other AI music generation models.
Performance
Generated using CassetteAI on fal, an AI model from CassetteAI.
Generation speed: The draft came back fast enough that iterating on prompts can feel closer to live tweaking than batch rendering.
Consistency across a track: The output held together across its length without the breaks or dropouts that can creep into longer generations.
Prompt detail: Spelling out instrumentation and tempo in the prompt, like the upright bass and 88 BPM pocket I asked for, carried through into the result.
Output format: Tracks come back as 44.1 kHz WAV files.
How to run CassetteAI on fal
You can run CassetteAI on fal through the API or test it in the browser playground.
Pass a prompt and a duration in seconds, and the model returns a signed URL to the WAV file.
Specifying musical detail like key, tempo, and instrumentation in the prompt gives the most usable results.
Pricing
CassetteAI costs $0.02 per output minute on fal.
#10: ACE-Step
Best for: Developers who want open-model flexibility with fine control over tags, lyrics, and the generation process at the lowest per-second cost.
Similar to: CassetteAI, Sonilo v1.1.
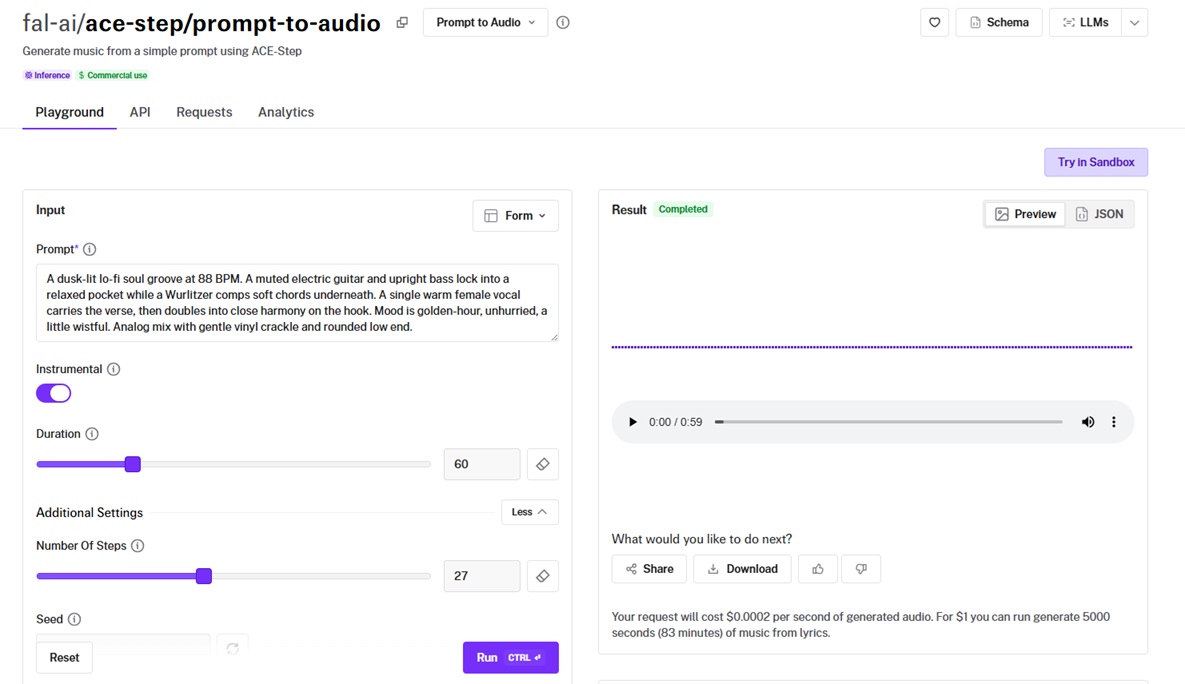
ACE-Step generates music from a simple prompt, turning your description into genre tags and lyrics automatically.
It exposes deep generation controls, from guidance type and scheduler to separate tag and lyric guidance scales, for developers who want to tune the output.
Performance
Generated using ACE-Step on fal, an AI model from ACE-Step.
Instrumental mode: Switching on instrumental gave me a vocal-free version of my prompt, and it turned out to be just as good as I expected.
Fine control: The separate tag and lyric guidance scales let you bias the result toward style or toward the words, which is quite granular.
Cost and length: At the lowest per-second price in this guide, it's built for high-volume generation, with duration set in seconds.
How to run ACE-Step on fal
On fal, ACE-Step is available through both the API and playground.
The simplest path is a single prompt with the instrumental toggle and a duration, and the model handles tags and lyrics for you.
For tighter control, the scheduler, guidance type, and the tag and lyric guidance scales are all adjustable per request.
Pricing
ACE-Step costs $0.0002 per second of generated audio on fal, which works out to roughly 83 minutes of music per dollar.
Recently Added




















Generate music at scale through a single API with fal
Picking the right text-to-music model comes down to what you're scoring, from a three-minute song with vocals to a 30-second ambient cue to a throwaway draft you'll regenerate twice.
Every one of them is a fal endpoint away, with pay-per-use pricing and no servers of your own to keep running.
The playground lets you hear outputs side by side before you commit to an endpoint.
You can create your free account and start generating on fal.
![10 Best Virtual Try-On APIs in 2026 [Reviewed] | fal](https://refinery.fal.media/url/https%3A%2F%2Fv3b.fal.media%2Ffiles%2Fb%2F0a9ec8c9%2F8GzWPYzjnpIp9l_nVysti_51daab936c734a849698a7fee8718d5e.jpg/tr:w-1080,q-80/8GzWPYzjnpIp9l_nVysti_51daab936c734a849698a7fee8718d5e.webp)

