Showing 28 of 1403 results

FLUX General Inpainting is a versatile endpoint that enables precise image editing and completion, supporting multiple AI extensions including LoRA, ControlNet, and IP-Adapter for enhanced control over inpainting results and sophisticated image modifications.
lora
controlnet
ip-adapter
image-to-image

iclight-v2
An endpoint for re-lighting photos and changing their backgrounds per a given description
relighting
editing
image-to-image
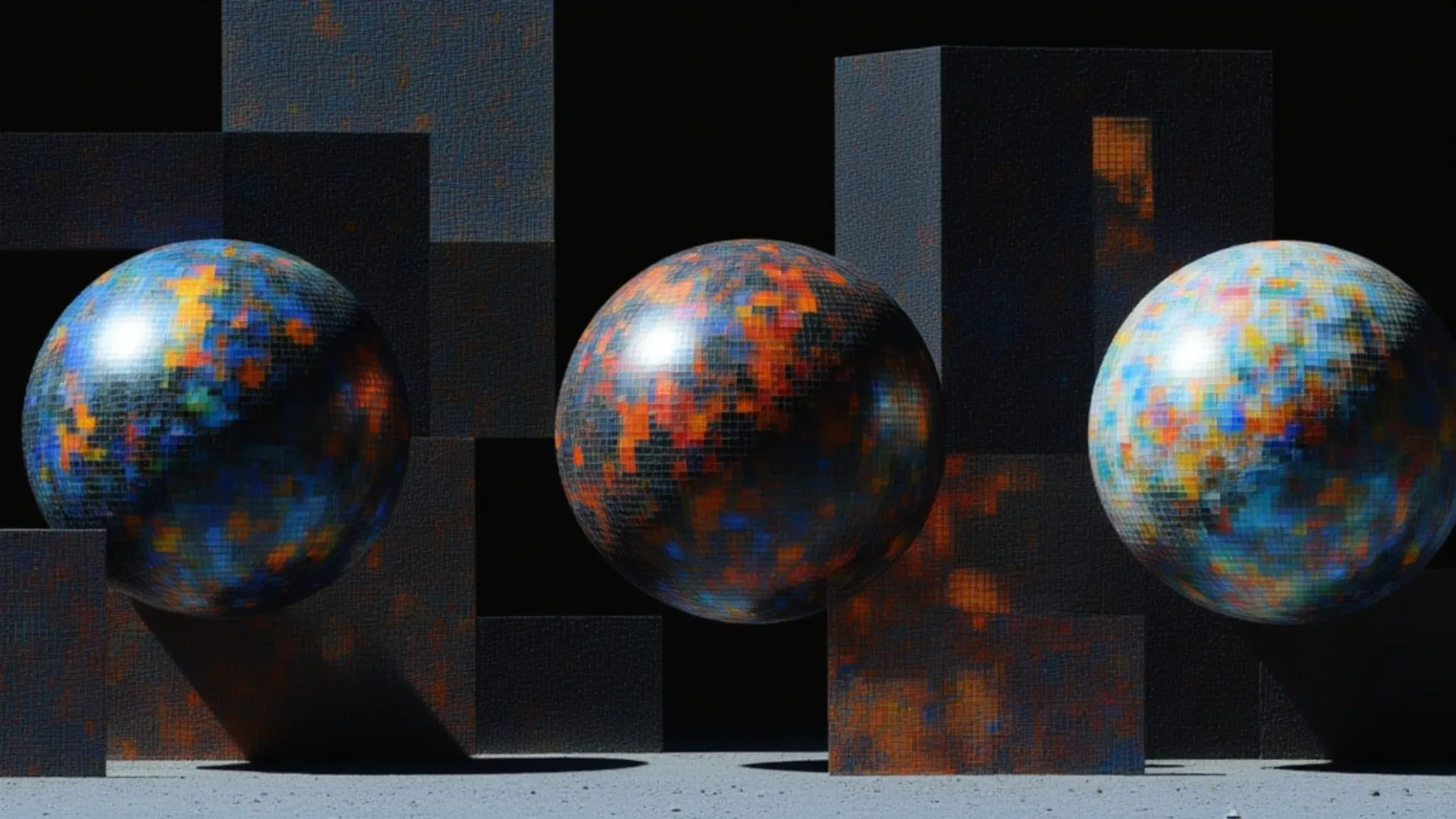
patina/material
Generate complete seamlessly tiling PBR materials including normal, roughness, basecolor, height and metalness maps up to 8K
material
pbr
displacement
text-to-image

Generate a video by taking a start frame and an end frame, animating the transition between them while following text-driven style and scene guidance.
image-to-video
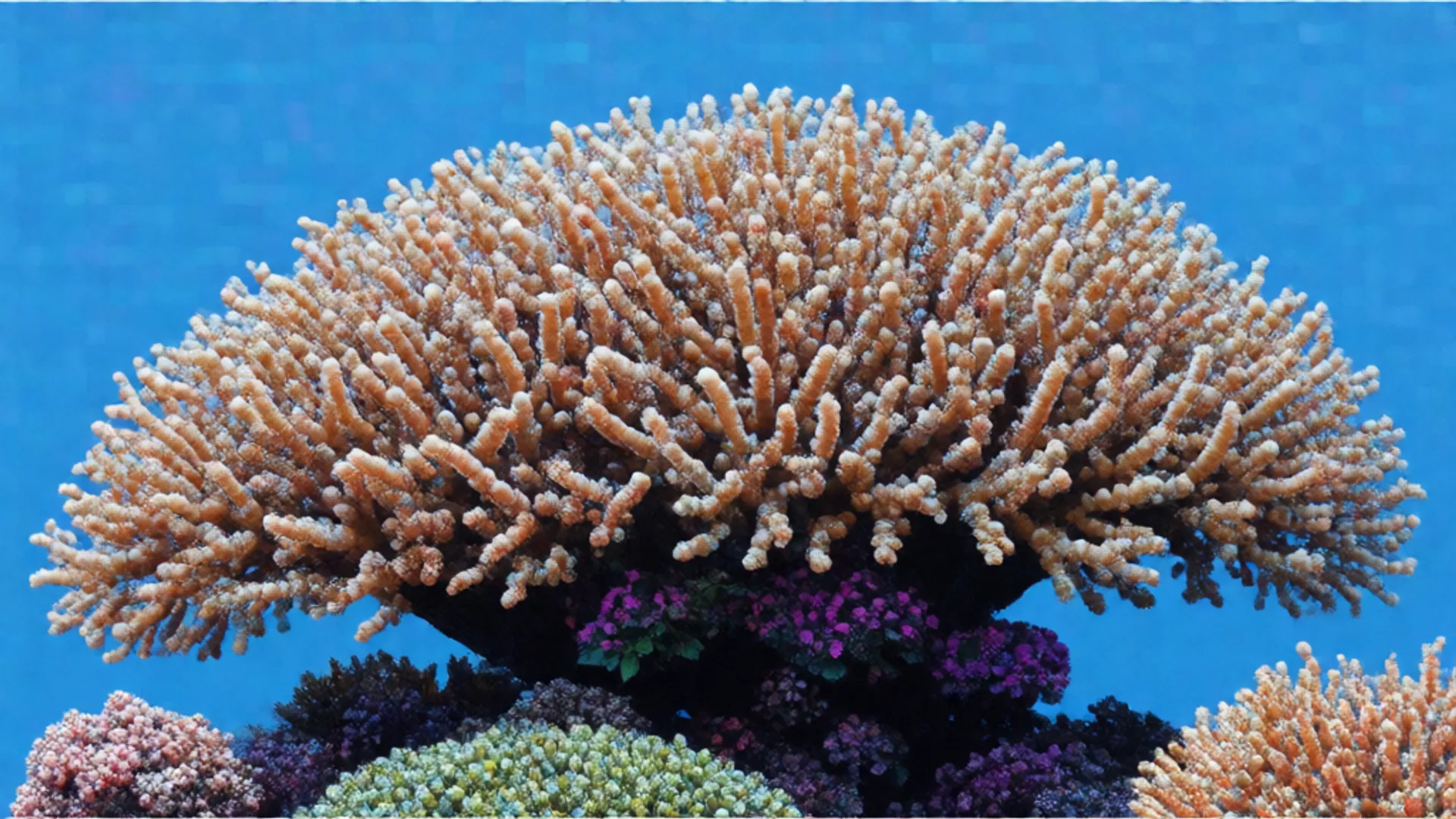
Extend existing images with Ideogram V3's reframe feature. Create expanded versions and adaptations while preserving main image and adding new creative directions through prompt guidance.
realism
typography
image-to-image

ace-step/prompt-to-audio
Generate music from a simple prompt using ACE-Step
text-to-music
text-to-audio

Create high-fidelity video with audio from images with LTX-2 Fast
image-to-video

sam2/auto-segment
SAM 2 is a model for segmenting images automatically. It can return individual masks or a single mask for the entire image.
segmentation
mask
image-to-image

imageutils/depth
Create depth maps using Midas depth estimation.
depth
utility
image-to-image

image-editing/photo-restoration
Restore and enhance old or damaged photos by removing imperfections, adding color while preserving the original character and details of the image.
stylized
transform
image-to-image

Inpainting Endpoint for the Qwen Edit Image editing model.
inpainting
qwen-image
image-to-image

Z-Image is the foundation model of the Z- Image family, engineered for good quality, robust generative diversity, broad stylistic coverage, and precise prompt adherence.
z-image
base
text-to-image

birefnet/v2/video
Video background removal version of bilateral reference framework (BiRefNet) for high-resolution dichotomous image segmentation (DIS)
utility
editing
video-to-video

Use Gemini TTS Models to convert your prompts to real audio.
text-to-speech
audio
gemini
text-to-audio

hunyuan-image/v3/text-to-image
Leverage the state-of-the-art capabilities of Hunyuan Image 3.0 to generate visual content that effectively conveys the messaging of your written material.
text-to-image

seedvr/upscale/image/seamless
Use SeedVR2 to upscale images, retaining seamless tiling
upscale
seamless
tiling
image-to-image
![Image-to-image editing with LoRA support for FLUX.2 [klein] 9B Base from Black Forest Labs. Specialized style transfer and domain-specific modifications.](https://refinery.fal.media/url/https%3A%2F%2Fv3b.fal.media%2Ffiles%2Fb%2F0a8b09b1%2F1lRmcLX6NOxTZp285RGPN_85a165d7a3cd4fbfba4c6302d341f0aa.jpg/tr:w-1920,q-80/1lRmcLX6NOxTZp285RGPN_85a165d7a3cd4fbfba4c6302d341f0aa.webp)
Image-to-image editing with LoRA support for FLUX.2 [klein] 9B Base from Black Forest Labs. Specialized style transfer and domain-specific modifications.
image-to-image
![FLUX.1 [dev] is a 12 billion parameter flow transformer that generates high-quality images from text. It is suitable for personal and commercial use.](https://refinery.fal.media/url/https%3A%2F%2Fstorage.googleapis.com%2Ffal_cdn%2Ffal%2Ffor%2520videos-4.jpg/tr:w-1920,q-80/for%20videos-4.webp)
FLUX.1 [dev] is a 12 billion parameter flow transformer that generates high-quality images from text. It is suitable for personal and commercial use.
text-to-image

GPT Image 1 mini combines OpenAI's advanced language capabilities, powered by GPT-5, with GPT Image 1 Mini for efficient image generation.
text-to-image

Transfer motion from a video to characters in an image using Dreamactor v2. Great performance for non-human and multiple characters
motion-control
dreamactor
video-to-video

recraft/v4.1/pro/text-to-image
Recraft V4.1 Pro pushes the V4.1 model into high-resolution territory — up to 2048×2048 and ultra-wide formats. Made for hero imagery, campaign work, and print, it preserves the same design taste at sizes ready for the final deliverable.
stylized
transform
typography
text-to-image

patina
PATINA creates seamless high-resolution normal, roughness, basecolor (albedo), height (displacement) and metalness maps from images
pbr
displacement
metalness
image-to-image
video-understanding
A video understanding model to analyze video content and answer questions about what's happening in the video based on user prompts.
utility
vision

stable-audio-3/medium/text-to-audio
Stable Audio 3 Medium is a 1.4 billion parameter latent diffusion model that generates high-quality stereo music up to 6 minutes from text prompts, trained on fully licensed data for safe commercial use.
music
audio
stereo
text-to-audio

moondream3-preview/query
Moondream 3 is a vision language model that brings frontier-level visual reasoning with native object detection, pointing, and OCR capabilities to real-world applications requiring fast, inexpensive inference at scale.
vision
vision

Generate videos from prompts and images using LTX Video-0.9.7 13B Distilled and custom LoRA
video
ltx-video
image-to-video

Generate high quality video clips from text and image prompts using PixVerse v5.5
image-to-video

Generate video clips from your prompts using Kling 2.0 Master
text-to-video
Showing 337 to 364 of 1403 results