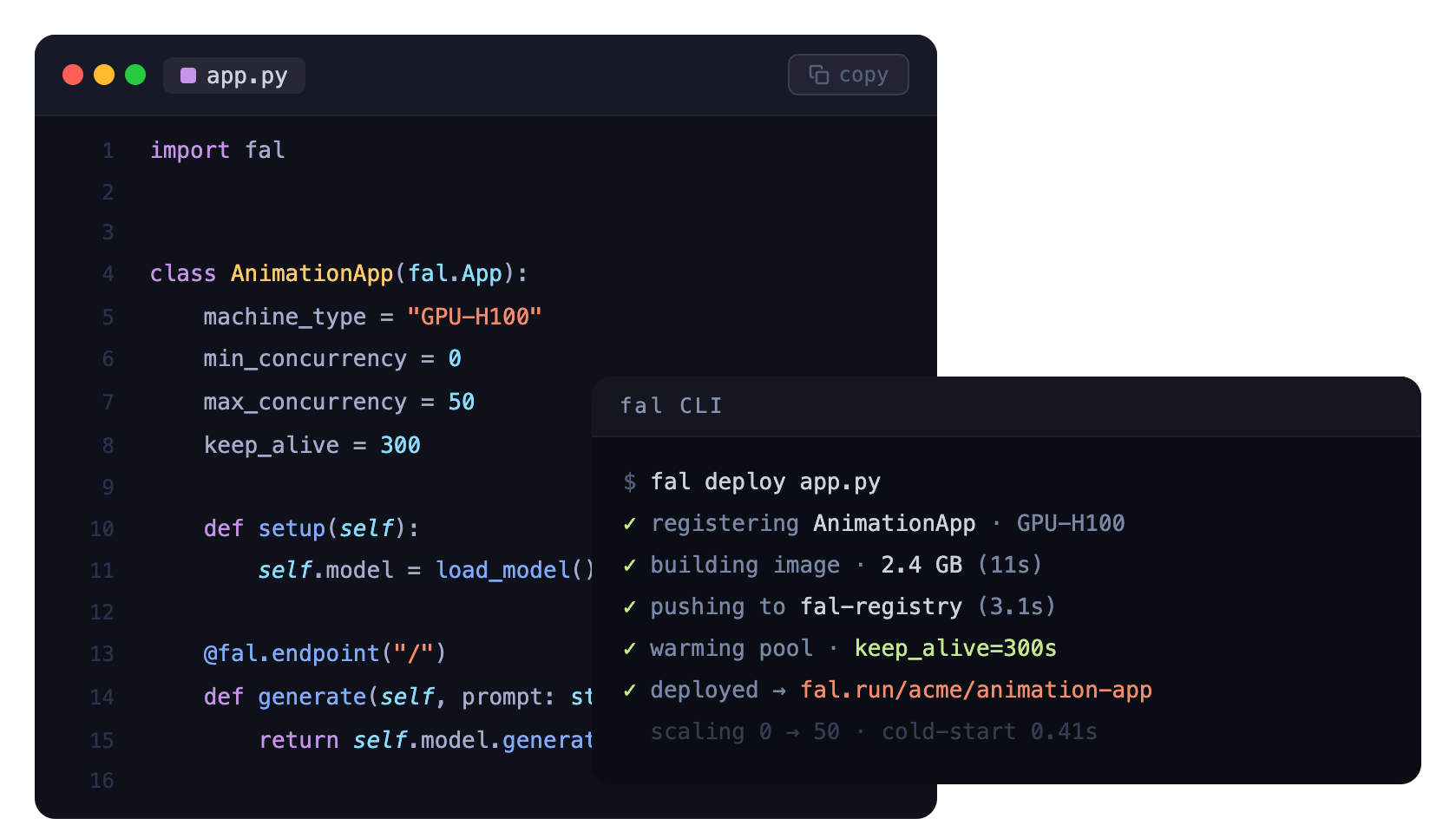
import fal
from pydantic import BaseModel, Field
from fal.toolkit import Image
class Input(BaseModel):
prompt: str = Field(
description="The prompt to generate an image from",
examples=["A professional image of a cat"],
)
class Output(BaseModel):
image: Image
class ImageGenerator(fal.App):
app_name = "image-generator"
machine_type = "GPU-H100"
min_concurrency=0
max_concurrency = 20
requirements = [
"hf-transfer==0.1.9",
"diffusers[torch]==0.32.2",
"transformers[sentencepiece]==4.51.0",
"accelerate==1.6.0",
]
def setup(self):
import torch
from diffusers import StableDiffusionXLPipeline
self.pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
).to("cuda")
# Warmup the model before the first request
self.warmup()
def warmup(self):
self.pipe("A professional image of a cat")
@fal.endpoint("/")
def run(self, request: Input) -> Output:
result = self.pipe(request.prompt)
image = Image.from_pil(result.images[0])
return Output(image=image)