Alibaba's HappyHorse-1.0, the AI video model that claimed the #1 spot on the Artificial Analysis Video Arena for both text-to-video and image-to-video, is going live on fal on April 26, 2026 at 9 PM PST. The model offers a unified 15B-parameter Transformer with joint audio-video generation, 1080p output, and multilingual lip-sync.

HappyHorse-1.0: a model nobody saw coming, just took the top spot on the most credible AI video benchmark available — and it's going live on fal on April 26, 2026 at 9 PM PST.
The video generation model appeared on the Artificial Analysis Video Arena around April 7, 2026, and immediately claimed the number one position in both text-to-video and image-to-video rankings (without audio).
Source of image. Screenshot taken on 13th of April, 2026.
And yet, in blind side-by-side comparisons judged by real users, it's supposedly outperforming models from well-funded labs with established track records.
Here's everything we know right now: what features to expect, what pricing might look like, and what's still unresolved.
What is HappyHorse-1.0?
HappyHorse-1.0 is an AI video generation model that handles both text-to-video and image-to-video through a single unified pipeline.
Across several sites associated with the model, the claimed specs include a 15-billion-parameter self-attention Transformer with 40 layers.
The architecture descriptions go further: the first and last 4 layers reportedly handle modality-specific embedding and decoding, while the middle 32 layers share parameters across text, image, video, and audio tokens.
All modalities reportedly sit in one token sequence with no cross-attention between separate branches.
The model also claims joint audio-video generation, producing dialogue, ambient sound, and Foley effects alongside the video in a single pass rather than adding audio as a post-processing step.
That said, none of these technical claims have been independently verified as of publication.
The weights aren't publicly downloadable, and no third party has confirmed the parameter count, the architecture details, or the inference speeds.
The claims themselves come from multiple sites, such as Happy Horse Art, with no clear indication of which is the primary source or whether any of them are run by the actual development team.
We'd recommend you treat everything in this section as claimed, not confirmed.
Who built HappyHorse-1.0's AI model?
Alibaba has been confirmed as the creator of HappyHorse-1.0, according to CNBC, as part of its ATH AI Innovation Unit.
For context, Alibaba is the company behind Qwen Image 2, which is available on fal.
How did it reach number one on the video leaderboard?
The Artificial Analysis Video Arena is a blind voting system.
Users see two videos generated from the same prompt and pick the one they prefer. They don't know which model made which video.
There are no labels, no brand names, and no context, which we think makes it a sound way of voting for the objectively better AI model.
Votes feed into an Elo rating system (the same math used in chess rankings), and when users consistently pick one model's output over another, that model's Elo score rises.
In theory, a model with no public team can rank above a model backed by a major lab if real users consistently prefer its output in blind tests.
That's exactly what happened with HappyHorse-1.0.
The pattern isn't unprecedented either. Anonymous pre-launch drops have become common in the Chinese AI ecosystem.
Earlier in 2026, a mystery model called Pony Alpha appeared on OpenRouter, triggered weeks of speculation, and turned out to be Z.ai's GLM-5 running a stealth stress test under a pseudonym.
Alibaba seems to have followed the same playbook with HappyHorse before announcing it as its own project.
What do the performance numbers look like?
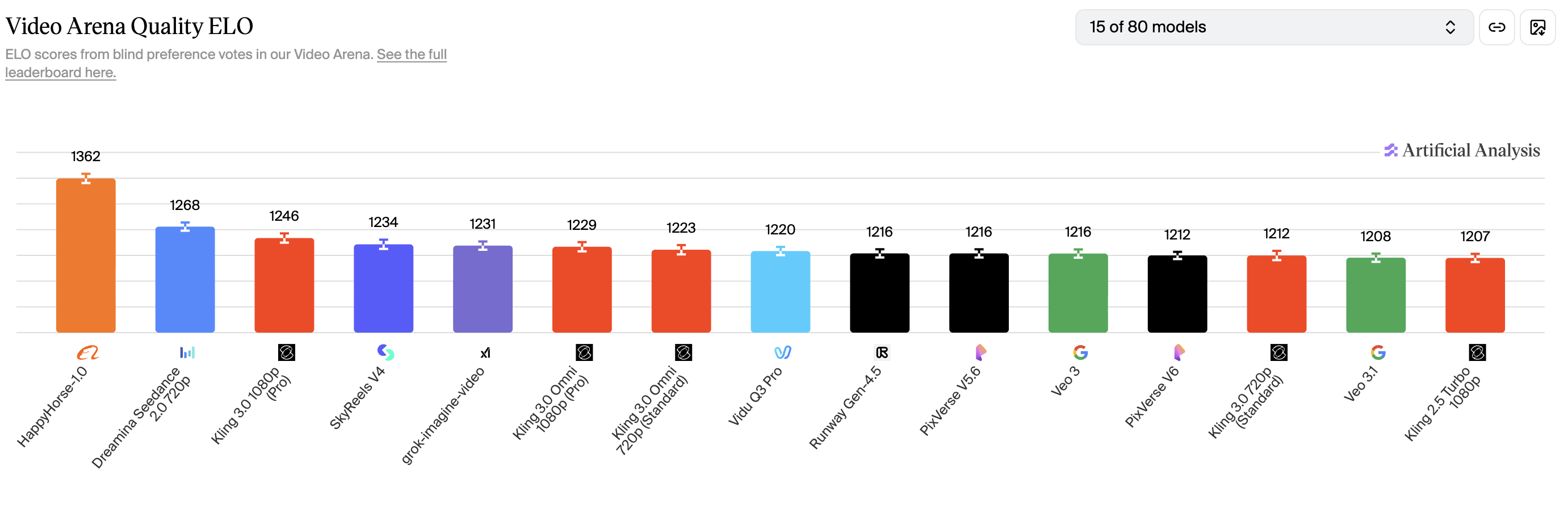
Here's where HappyHorse-1.0 sits on the Artificial Analysis Video Arena Quality ELO ranking as of 13th of April, 2026.
| Rank | Model | Elo |
|---|---|---|
| #1 | HappyHorse-1.0 | 1381 |
| #2 | Dreamina Seedance 2.0 720p | 1274 |
| #3 | SkyReels V4 | 1243 |
| #4 | Kling 3.0 1080p (Pro) | 1242 |
| #5 | Kling 3.0 Omni 1080p (Pro) | 1228 |
| #6 | grok-imagine-video | 1227 |
| #7 | Vidu Q3 Pro | 1223 |
| #8 | Runway Gen-4.5 | 1223 |
| #9 | PixVerse V5.6 | 1221 |
| #10 | Kling 3.0 Omni 720p (Standard) | 1218 |
| #11 | Veo 3 | 1217 |
| #12 | Kling 3.0 720p (Standard) | 1214 |
| #13 | Kling 2.5 Turbo 1080p | 1210 |
| #14 | PixVerse V6 | 1210 |
| #15 | Veo 3.1 Fast | 1209 |
Data from the Artificial Analysis Video Arena. Elo ratings are recomputed continuously as new votes come in. Snapshot as of 13th of April, 2026.
That's a 107-point gap over the second-place model.
In Elo terms, a gap that size means users prefer HappyHorse's output roughly 65% of the time in head-to-head blind matchups.
And the lead has actually widened since the model first appeared on the arena in early April, when the gap was around 60 points.
The picture doesn't really change when audio enters the evaluation: HappyHorse-1.0 has achieved 1238 Elo.
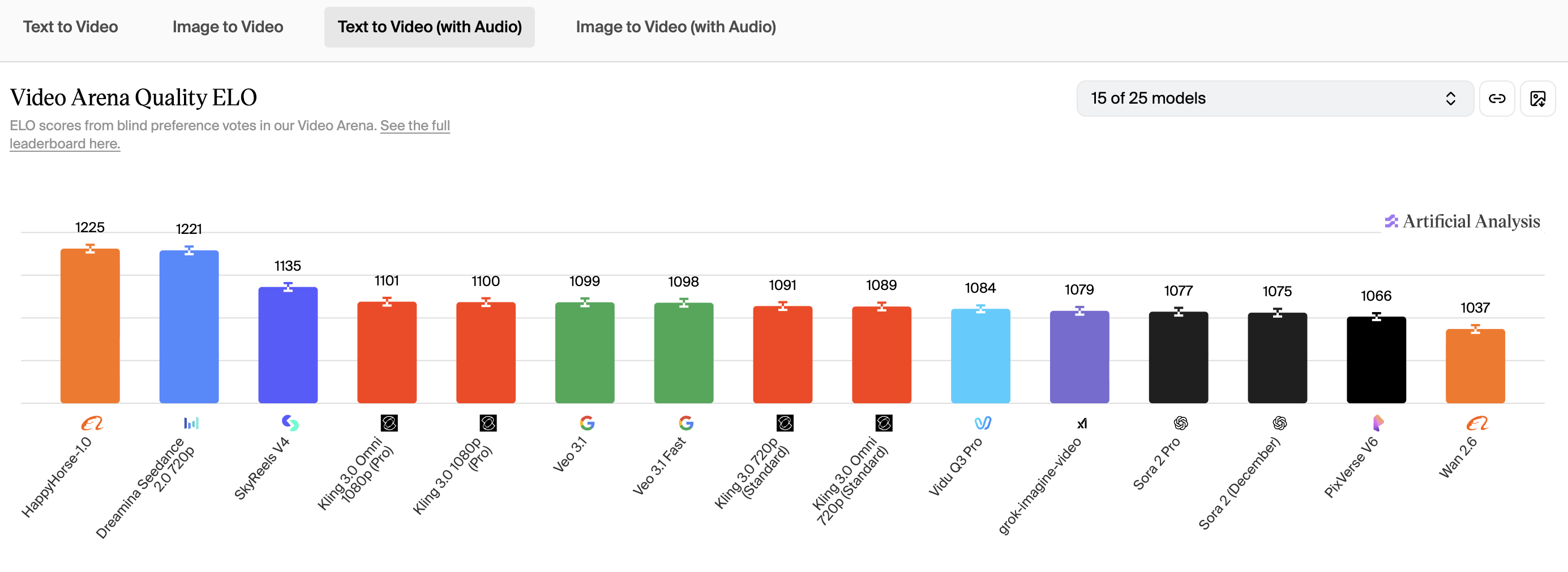
Data from the Artificial Analysis Video Arena. Elo ratings are recomputed continuously as new votes come in. Snapshot as of 13th of April, 2026.
What features can we expect?
Based on what should be the official HappyHorse site (we weren't able to independently verify if this is the official website) and the data visible from the leaderboard, here's what the model appears to offer.
-
Text-to-video and image-to-video in one model: The leaderboard listings confirm both T2V and I2V under the same model name, consistent with a unified pipeline rather than separate specialized models.
-
Joint audio-video generation: The model ranks in both the "with audio" and "without audio" categories on the leaderboard, which confirms audio generation exists.
-
1080p output: The site claims 5 to 8 second clips at 1080p in standard aspect ratios (16:9 and 9:16). Self-reported inference speeds suggest roughly 38 seconds for a 1080p clip on a single H100, though this hasn't been tested independently.
-
Multilingual lip-sync: The model's associated sites list seven supported languages for native lip-sync: English, Mandarin, Cantonese, Japanese, Korean, German, and French.
-
8-step distilled inference: The site describes a DMD-2 distillation process that reduces denoising to just 8 steps without classifier-free guidance. If accurate, this would explain competitive generation speeds at the 15B parameter scale. But again, unverified until the weights are public.
What will pricing look like on fal?
Pricing for HappyHorse-1.0 on fal hasn't been announced yet.
But to give you a frame of reference, here's how comparable AI video generators are currently priced on the platform.
Video generation on fal uses pay-as-you-go pricing. No subscriptions, no minimum commitments, and no idle costs.
You pay per second of generated video or per output, and the rate depends on the model, the resolution, and whether audio generation is enabled.
Here's what the current range looks like across models already on fal:
| Model | Pricing | Notes |
|---|---|---|
| Wan 2.5 | $0.05/second | Budget end of the spectrum |
| Hailuo-02 Standard (768p) | $0.045/second | Mid-range, standard resolution |
| Hailuo-02 Pro (1080p) | $0.08/second | Mid-range, full HD |
| PixVerse V5.6 (720p) | $0.45 per 5s clip | Without audio |
| PixVerse V5.6 (1080p) | $0.75 per 5s clip | Without audio |
| Kling 2.1 Pro | $0.098/second | Image-to-video |
| Seedance 1.0 Pro (1080p) | ~$0.74 per 5s clip | Token-based pricing |
| Veo 3 Fast (no audio) | $0.10/second | Google's model, fast mode |
| Veo 3 (full quality) | $0.40/second | With audio capability |
| Sora 2 Pro (720p) | $0.30/second | Premium tier |
| Sora 2 Pro (1080p) | $0.50/second | Top of the range |
Given HappyHorse's positioning as a top-tier model with 1080p output and joint audio generation, you'd likely expect pricing somewhere in the mid-to-upper range of that spectrum.
We'll update this section with confirmed pricing once HappyHorse-1.0 goes live on fal.
falMODEL APIs
The fastest, cheapest and most reliable way to run genAI models. 1 API, 100s of models
Try HappyHorse-1.0 on fal — live April 26 at 9 PM PST
HappyHorse-1.0 goes live on fal on April 26, 2026 at 9 PM PST, accessible through the same API that powers over 600 other production-ready AI models.
That means you'll be able to access it through the same unified API that serves models like Kling, Veo 3, Sora 2, and Seedance. One API key, one billing system, no infrastructure to manage.
fal's custom inference engine writes CUDA kernels optimized for specific model architectures, which typically means faster generation times and lower cold starts than self-hosting or using general-purpose inference platforms.
Whether those optimizations apply to HappyHorse's specific architecture is still being evaluated, but it's the same approach that gets FLUX images generating in under 2 seconds and cold starts down to 5 to 10 seconds across the platform.
Head to fal at 9 PM PST on April 26 to try it.
Frequently Asked Questions about HappyHorse-1.0
Is HappyHorse-1.0 available to use right now?
HappyHorse-1.0 goes live on fal on April 26, 2026 at 9 PM PST. From that point on, it's accessible through the same API you'd use for any other video model on the platform.
Is HappyHorse-1.0 actually the best AI video model?
It depends on what you're measuring. On the Artificial Analysis Video Arena, users prefer HappyHorse's output over every other model across both visual-only and with-audio rankings.
The lead is largest on visual quality and narrower, but still present when audio is included. Elo also doesn't measure API reliability, cost, latency, or uptime, all of which matter for production use.
Why did HappyHorse-1.0 rank #1 on the video leaderboard?
The reason why HappyHorse-1.0 ranks #1 on the Artificial Analysis Video Arena is that users preferred its videos over those of other AI models.
It is a blind voting system environment, where users are shown 2 videos, and they have to select which one they prefer.
Is HappyHorse-1.0 going to be open source?
HappyHorse-1.0's team has announced open-source availability with commercial licensing, but no weights or licenses have been published.
What languages does HappyHorse support for lip-sync?
The model's associated sites list seven: English, Mandarin, Cantonese, Japanese, Korean, German, and French.
These claims haven't been independently tested because there's no public access to the model yet.
The latest "with audio" leaderboard rankings show HappyHorse leading on T2V with audio by 14 Elo points over Seedance 2.0, suggesting the lip-sync and audio capabilities are genuinely competitive.






















