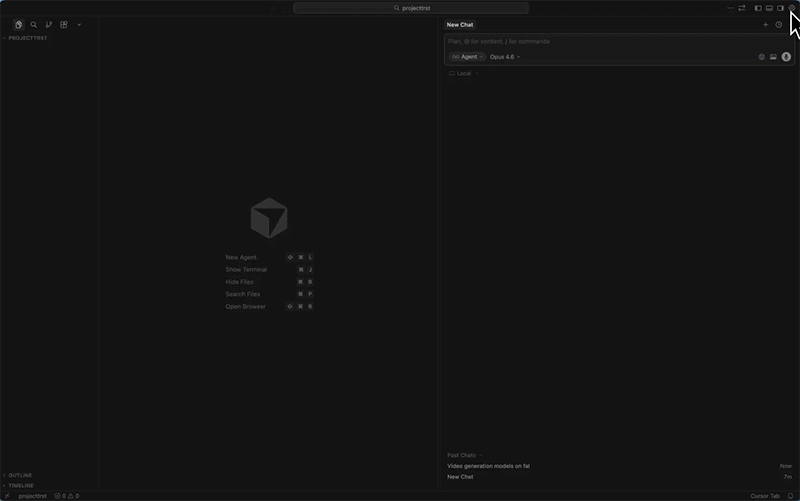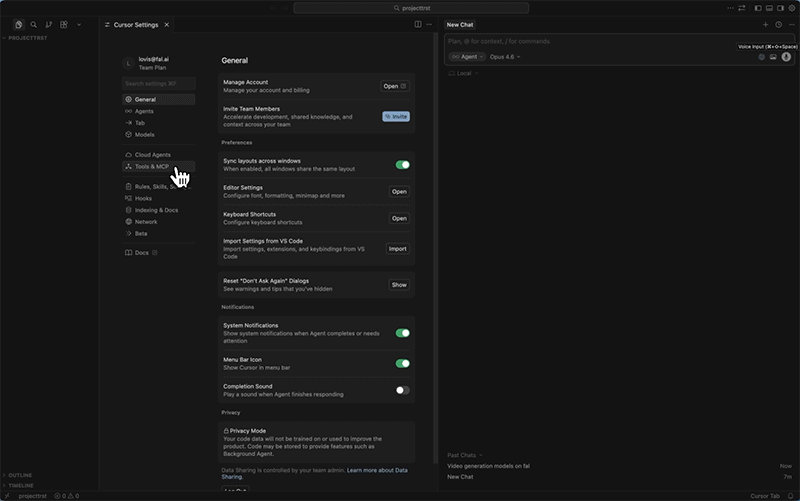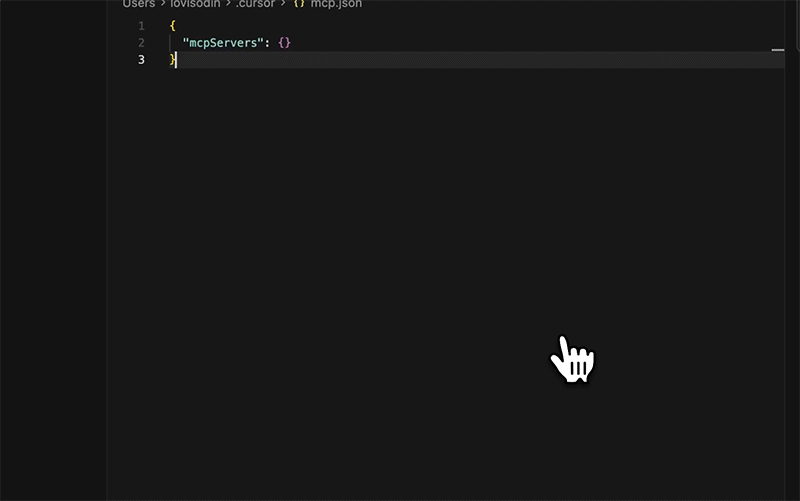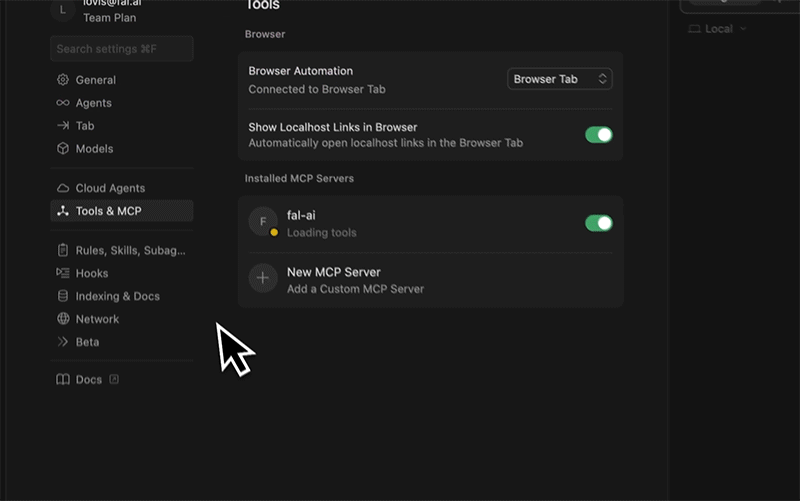
mcp.fal.ai/mcp and works with any client that supports the Model Context Protocol, including Claude Code, Claude Desktop, Cursor, Windsurf, and more. Every request uses your own API key — nothing is stored on the server.
You need a fal API key to use the MCP server. If you don’t have one yet, create one here.
Setup
- Claude Code
- Claude Desktop
- Cursor
- Windsurf
- Other MCP Clients
Run this command in your terminal:That’s it. Claude Code will now have access to all fal tools.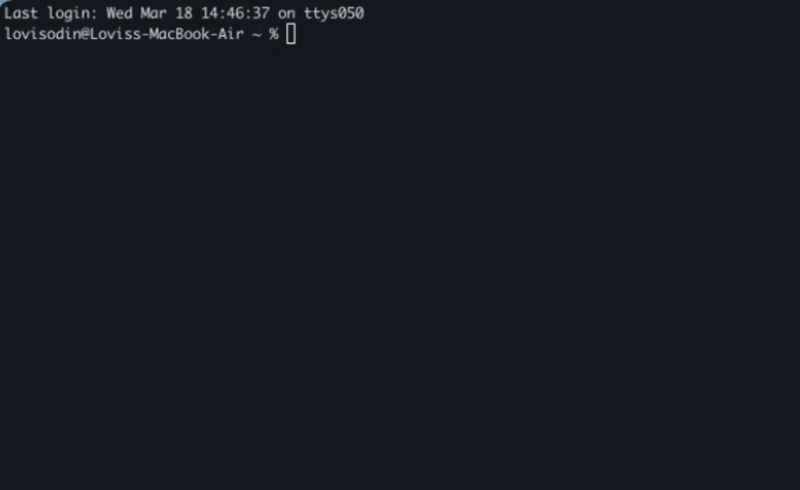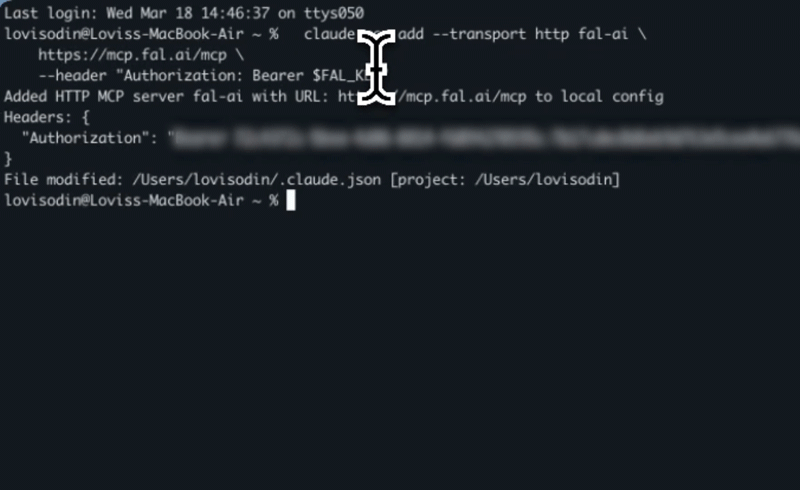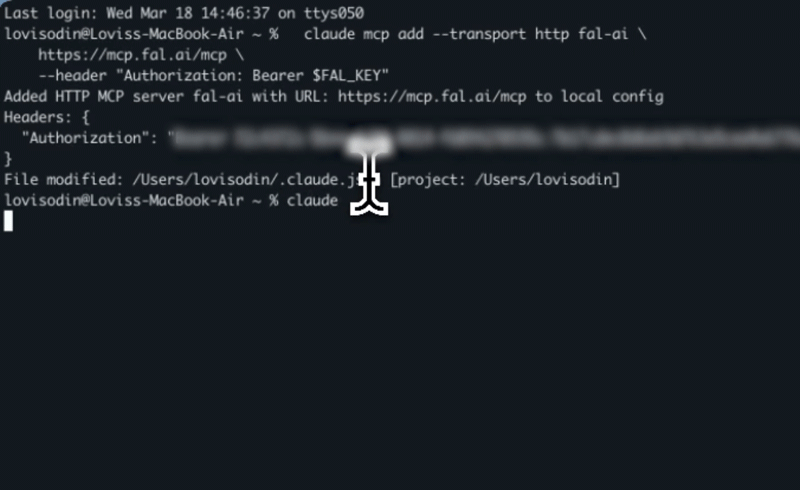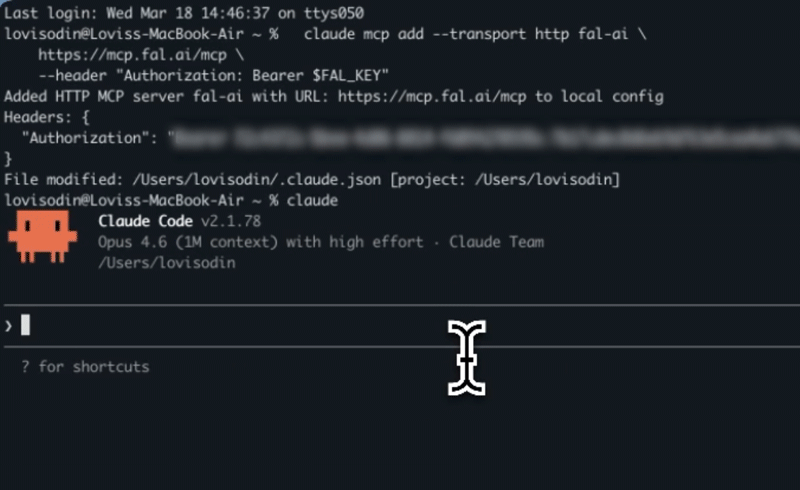
Available Tools
The MCP server exposes 9 tools organized in three categories. Your AI assistant picks the right tool automatically based on what you ask.Discovery
Execution
Utility
Examples
Here are concrete examples of what you can ask your AI assistant once the MCP server is connected.Generate an image
“Generate a photorealistic image of a mountain lake at golden hour using fal”The assistant will:
- Use
search_modelsto find image generation models - Use
get_model_schemato check the parameters for the chosen model - Use
run_modelto generate the image - Return the image URL
Generate a video from an image
“Take this image and turn it into a 5-second cinematic video”The assistant will:
- Use
upload_fileto upload your image to fal’s CDN - Use
recommend_modelto find the best image-to-video model - Use
submit_job(since video generation takes longer) - Use
check_jobto poll for the result
Check pricing before running
“How much does it cost to generate a video with Kling 3.0?”The assistant will call
get_pricing with fal-ai/kling-video/v3/pro/image-to-video and return the per-run cost.
Find the right model
“What’s the best model for removing backgrounds from product photos?”The assistant will call
recommend_model with your task description and return a ranked list of models with tips on how to use them.
Search the docs
“How do I set up webhooks with fal?”The assistant will call
search_docs and return relevant guides and code examples from the fal documentation.
How It Works
The MCP server is a stateless API hosted on Vercel. Each request is fully isolated:- Your AI assistant sends a request to
mcp.fal.ai/mcpwith your API key - The server calls the fal Platform API on your behalf
- Results are returned to your assistant, which formats them for you
Authorization header and is never stored. The server has no sessions, no state, and no access to anything beyond what the fal public API provides with your key.
Tool Reference
search_models
Search fal’s model catalog by keyword, category, or both. Parameters:
Example response:
get_model_schema
Get the full input/output schema for a specific model. Use this beforerun_model to understand what parameters are accepted.
Parameters:
run_model
Run any fal model. Submits to the queue, polls until complete, and returns the result. Parameters:
Example:
For long-running models (video, 3D, training), use
submit_job + check_job instead to avoid timeouts.submit_job
Submit a job without waiting for the result. Returns immediately with arequest_id you can use with check_job.
Parameters:
check_job
Check the status of a running job, fetch the result, or cancel it. Parameters:upload_file
Upload a file to fal’s CDN so it can be used as input to models. Accepts a URL to a remote file. Parameters:
Returns a
cdn_url that you can pass to any model parameter that accepts a URL (e.g. image_url, audio_url).
get_pricing
Get the cost of running a model. Parameters:recommend_model
Describe what you want to create and get model recommendations ranked by popularity. Parameters:search_docs
Search the fal documentation for guides, API references, and code examples. Parameters:FAQ
- What models can I use?
- Is my API key stored?
- Does it cost extra?
- What about rate limits?
All 1,000+ models in the fal catalog — image generation, video, audio, speech, 3D, LLMs, and more. Use
search_models or recommend_model to find what you need.