How Context Propagation Works
The W3C Trace Context standard defines atraceparent header that carries a trace ID and parent span ID between services. The sending app injects the current span context into a carrier (a plain dict), passes it to the receiving app, and the receiving app extracts the context before creating its span. Both apps end up contributing spans to the same trace ID.
fal apps communicate over HTTP, and the carrier is passed as a field in the JSON request body. Both apps must export to the same OTLP backend for the spans to be correlated.
Setup
DeployTextToImageWorker first to get its app id, then deploy ImagePipeline and pass the app id when calling it.
OTEL_EXPORTER_OTLP_ENDPOINT and OTEL_EXPORTER_OTLP_HEADERS set as fal secrets. See Custom Traces for backend options and how to store credentials.
Implementation
Python
Resulting Trace
Both apps export to the same backend using the same trace ID. The trace appears as:inference span in TextToImageWorker is a child of image-pipeline in ImagePipeline because _propagator.extract(input.trace_context) reconstructed the parent context before the span was created.
The entity map shows both apps connected, and the span tree shows spans from both services under the same trace ID:
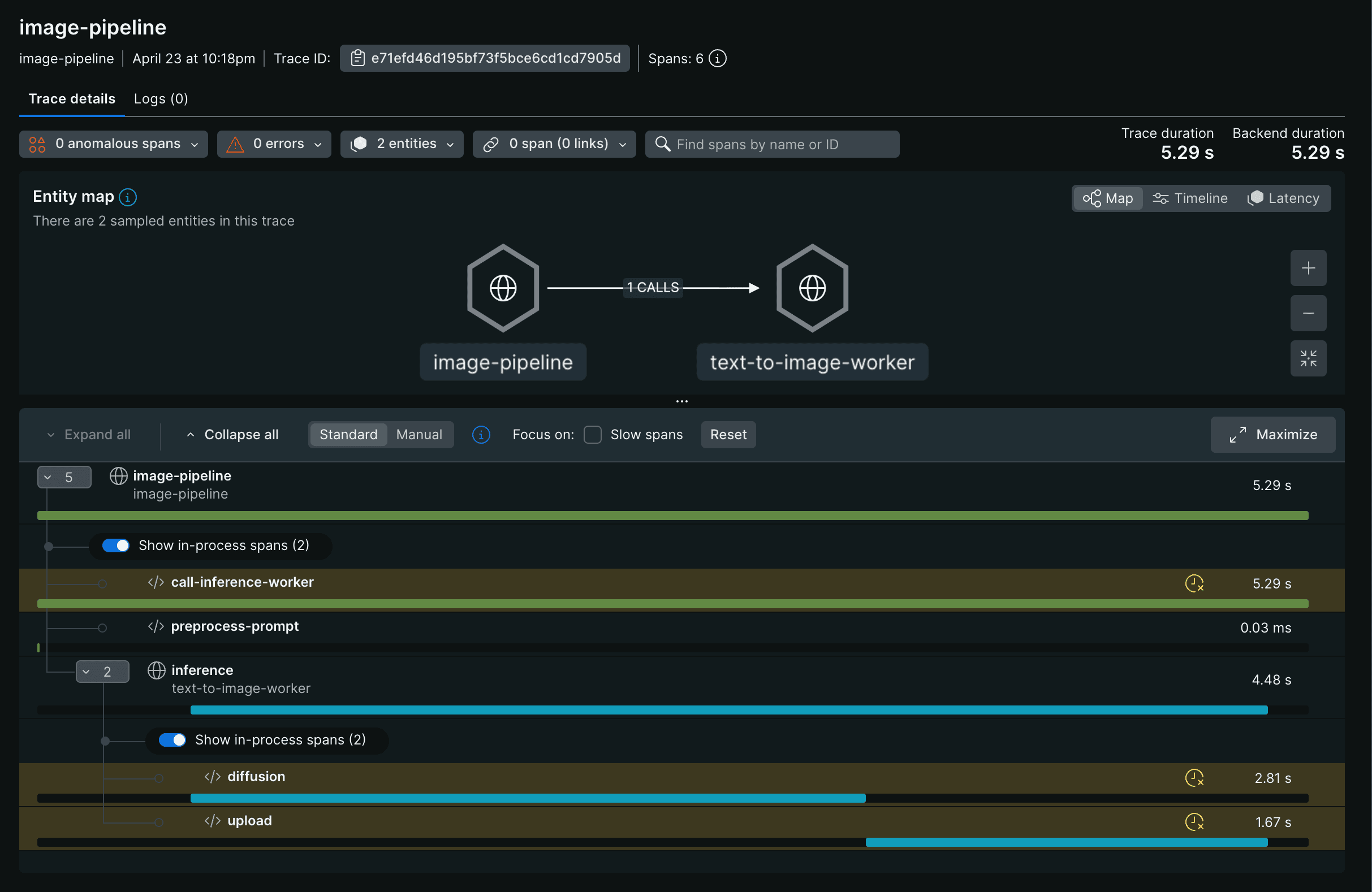
Both apps must export to the same OTLP backend for the trace to appear connected. If each app sends spans to a different backend, they will not be correlated even though they share a trace ID.
What’s Next
Custom Traces
Instrument a single app with spans for each inference stage
Production Configuration
Sampling, batch export tuning, and graceful flush on shutdown