 Works in both card view and list view, and stacks with environment and tag filtering so you can find what needs your attention faster.
Works in both card view and list view, and stacks with environment and tag filtering so you can find what needs your attention faster.
Works in both card view and list view, and stacks with environment and tag filtering so you can find what needs your attention faster.
Works in both card view and list view, and stacks with environment and tag filtering so you can find what needs your attention faster.
 The Serverless apps page now opens with an aggregate analytics dashboard that summarizes capacity, traffic, and per-app activity across every app you own in one place.
* **GPU and CPU distribution** charts visualize how your active runners are split across machine types (H100, A100, L40, B200, CPU types, etc.)
* **Live capacity tiles** show total **Active Runners, Queued Requests, GPUs, and CPUs**, each annotated with how many apps contribute to the number
* **Status code, request traffic, and concurrent request** charts plot aggregate request health over your selected window
* **Top Apps** lists your highest-volume apps over the window for quick drill-in
* **Requests by app** is a new stacked chart that breaks aggregate traffic down per app, with a searchable legend you can click to isolate a single app or flip to an **Errors** view
The Serverless apps page now opens with an aggregate analytics dashboard that summarizes capacity, traffic, and per-app activity across every app you own in one place.
* **GPU and CPU distribution** charts visualize how your active runners are split across machine types (H100, A100, L40, B200, CPU types, etc.)
* **Live capacity tiles** show total **Active Runners, Queued Requests, GPUs, and CPUs**, each annotated with how many apps contribute to the number
* **Status code, request traffic, and concurrent request** charts plot aggregate request health over your selected window
* **Top Apps** lists your highest-volume apps over the window for quick drill-in
* **Requests by app** is a new stacked chart that breaks aggregate traffic down per app, with a searchable legend you can click to isolate a single app or flip to an **Errors** view
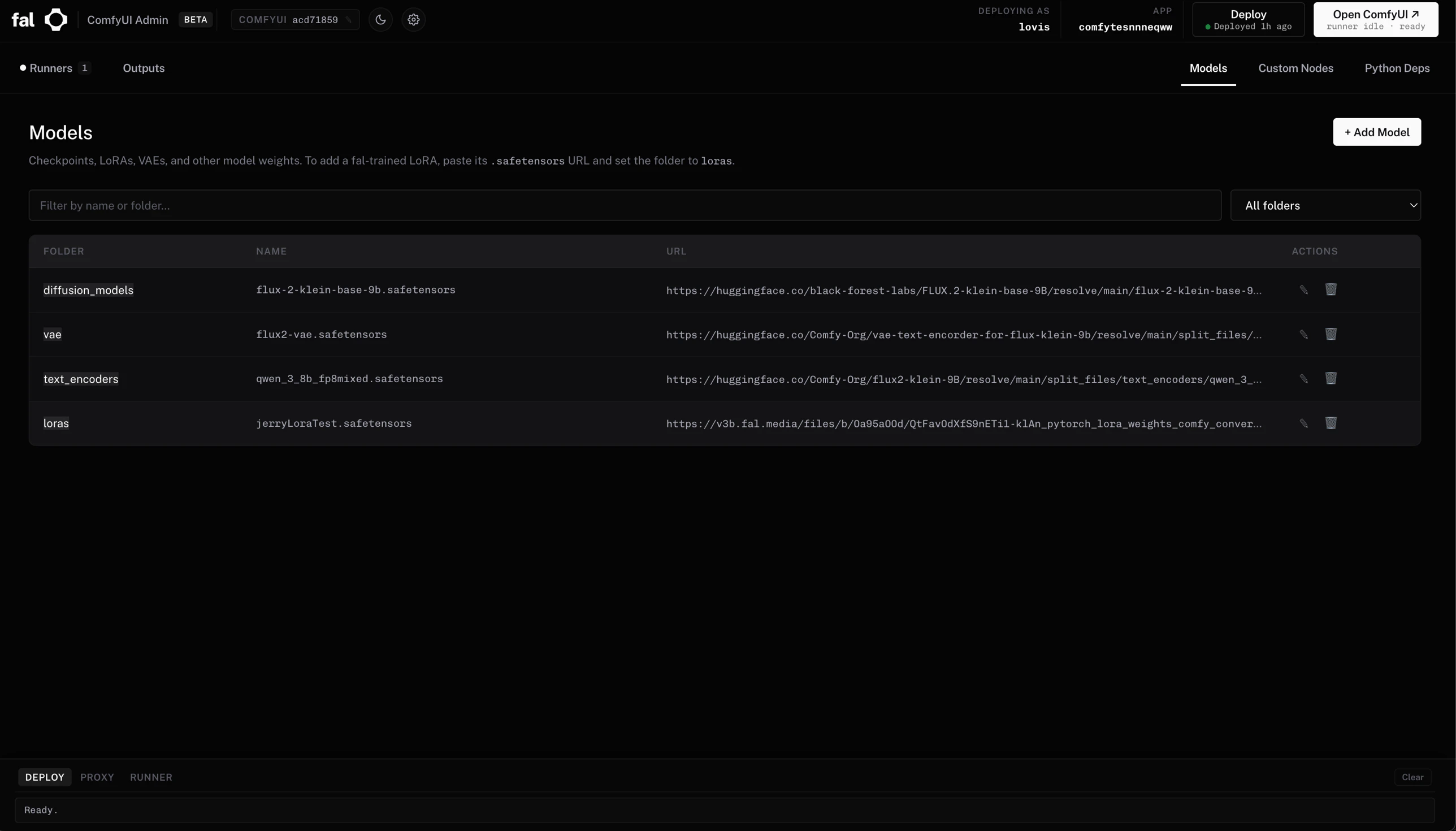 The launcher auto-installs `uv` and Python 3.11 on first run — no Python knowledge required from end users. Works on macOS and Windows.
[Read the guide →](/examples/image-generation/run-comfyui-visual)
The launcher auto-installs `uv` and Python 3.11 on first run — no Python knowledge required from end users. Works on macOS and Windows.
[Read the guide →](/examples/image-generation/run-comfyui-visual)
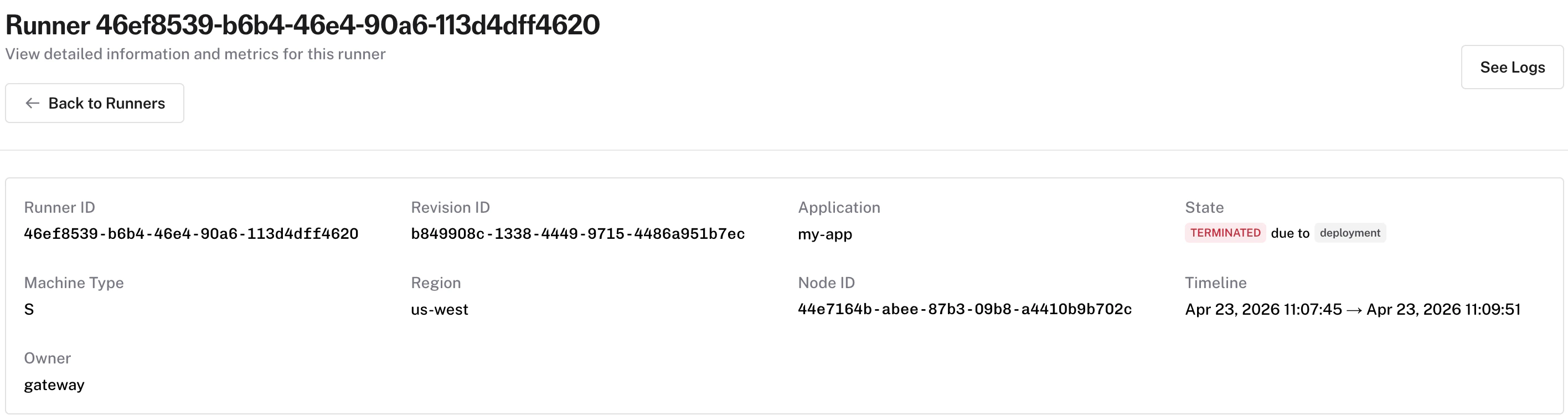 * **Runner list** — surfaces the same reason via a tooltip on the state badge, so you can scan failures without opening each runner
* **Runner list** — surfaces the same reason via a tooltip on the state badge, so you can scan failures without opening each runner
 * **Runner events timeline** — event rows display the termination reason as a highlighted badge alongside the status text
* **Runner events timeline** — event rows display the termination reason as a highlighted badge alongside the status text
 Please note that in some cases the termination reason may be unknown. When that happens, no reason badge or tooltip is shown.
Please note that in some cases the termination reason may be unknown. When that happens, no reason badge or tooltip is shown.
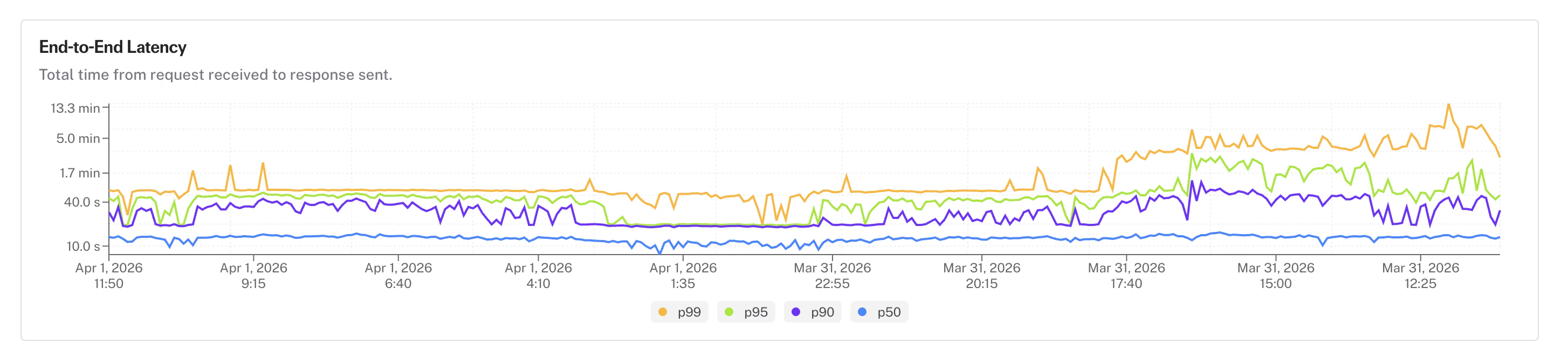 * The [analytics page](/documentation/serverless/observability/app-analytics) now includes a **latency percentile chart** showing p50, p90, p95, and p99 request latency over time
* Quickly spot latency regressions or tail-latency spikes at a glance
* The [analytics page](/documentation/serverless/observability/app-analytics) now includes a **latency percentile chart** showing p50, p90, p95, and p99 request latency over time
* Quickly spot latency regressions or tail-latency spikes at a glance
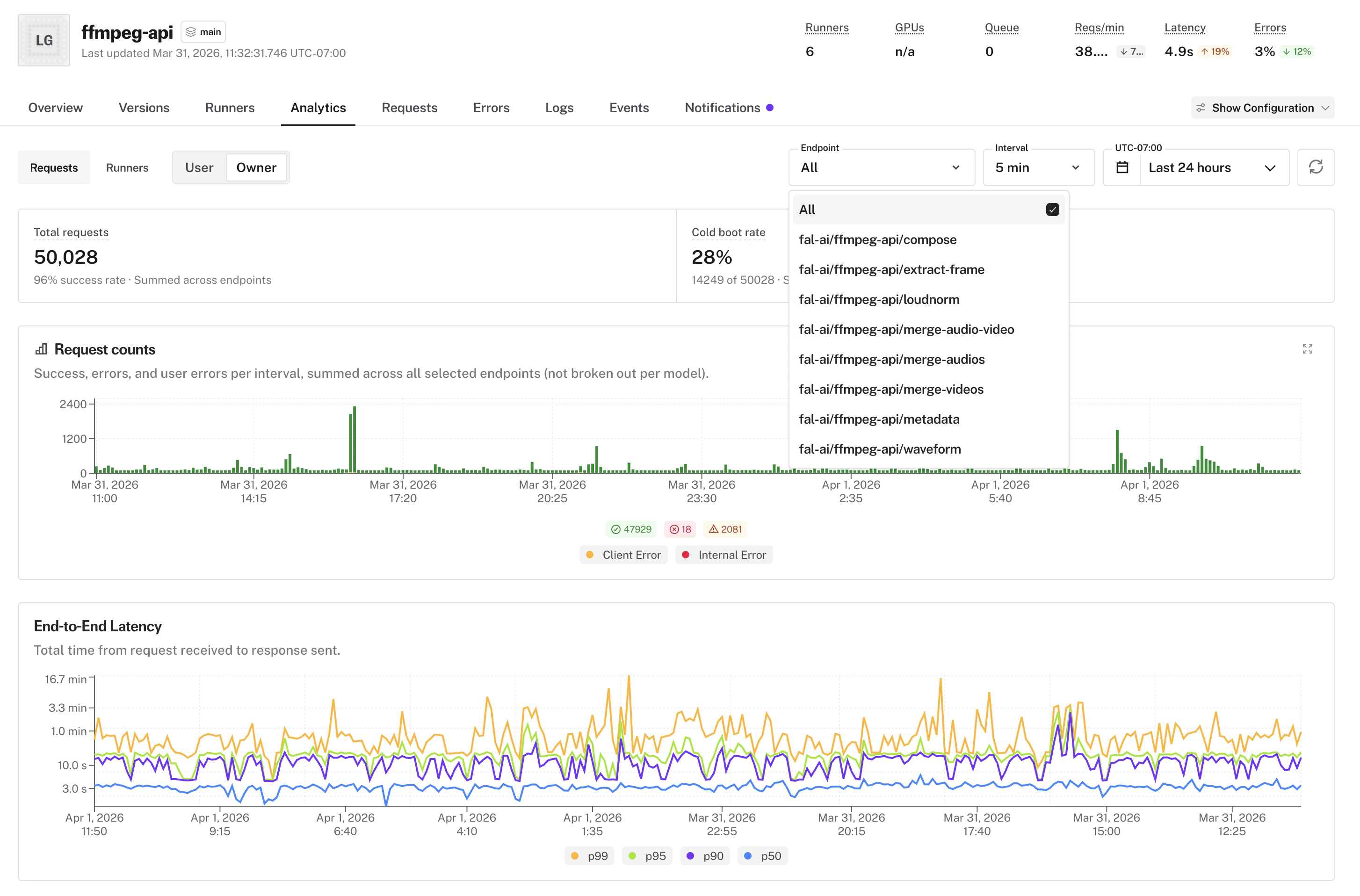 * Select **"All" endpoints** in [App Analytics](/documentation/serverless/observability/app-analytics) to see metrics aggregated across every endpoint at once
* Aggregation works across request counts, error rates, percentile charts, and gateway stats, so you can get a full picture of your app's performance without switching between endpoints
* Select **"All" endpoints** in [App Analytics](/documentation/serverless/observability/app-analytics) to see metrics aggregated across every endpoint at once
* Aggregation works across request counts, error rates, percentile charts, and gateway stats, so you can get a full picture of your app's performance without switching between endpoints
 * The [apps page](/documentation/deployment/manage-deployments) now shows an **aggregate metrics bar** with total runners, queue depth, and GPU distribution, giving you a quick overview of your resource usage without clicking into each app
* **Per-app GPU and queue columns** in both card view and list view make it easy to compare usage across apps at a glance
* The [apps page](/documentation/deployment/manage-deployments) now shows an **aggregate metrics bar** with total runners, queue depth, and GPU distribution, giving you a quick overview of your resource usage without clicking into each app
* **Per-app GPU and queue columns** in both card view and list view make it easy to compare usage across apps at a glance
 * **Filter [logs](/serverless/development/logging) by endpoint** to focus on a specific route
* A new **Source column** shows which endpoint or system action produced each log line
* **Filter [logs](/serverless/development/logging) by endpoint** to focus on a specific route
* A new **Source column** shows which endpoint or system action produced each log line
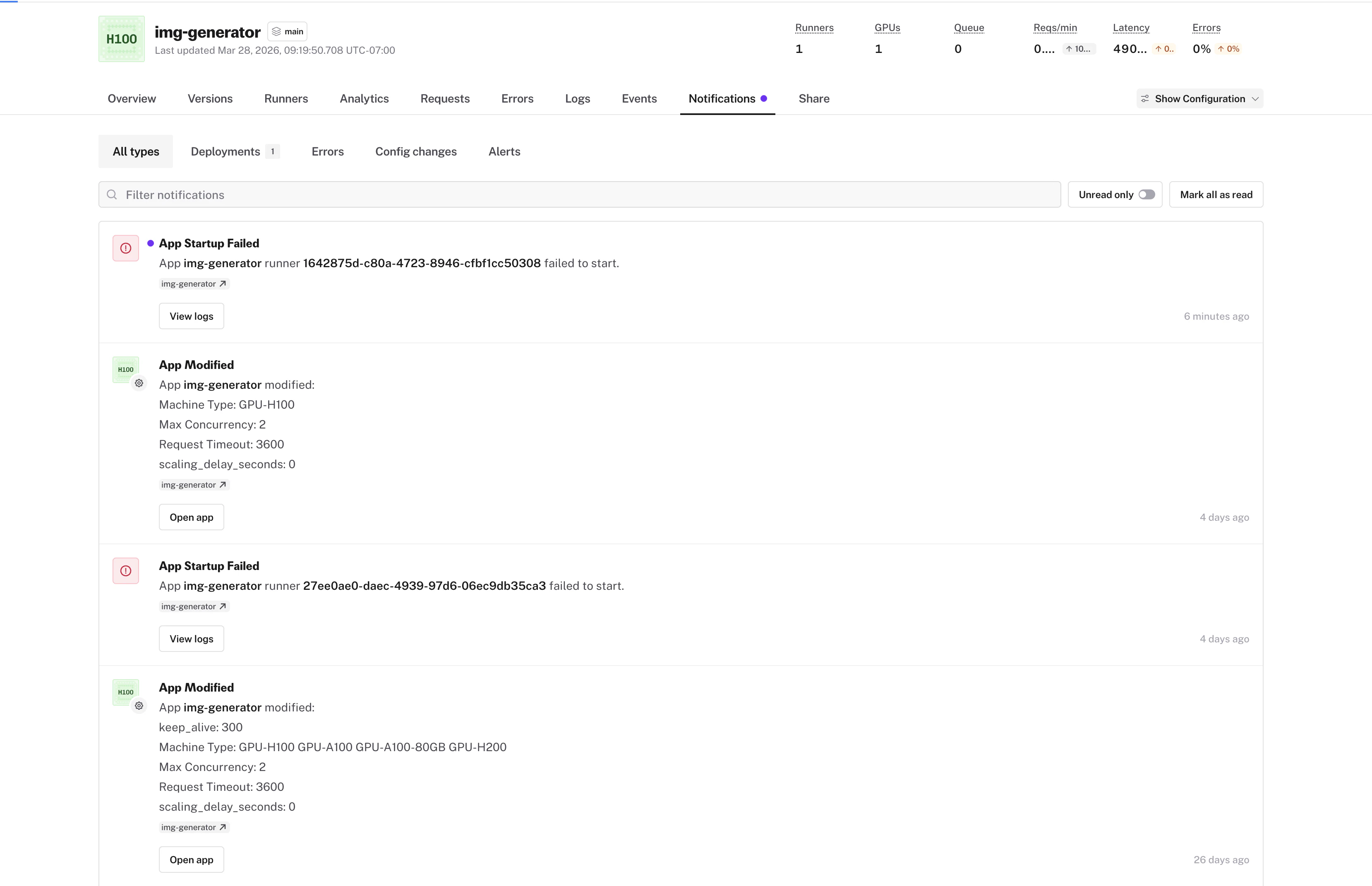 * **Redesigned notification dropdown** so you can stay on top of issues without leaving the page you're on
* **Category filtering** lets you cut through noise and focus on the notification types that matter to you
* **Pagination** so you can browse your full notification history without losing your place
* **Mark all as read** to quickly clear your inbox when you've caught up
* **OOM alerts** notify you when a runner runs out of memory, so you can resize before it impacts users
* **Notification badge on app tabs** shows unread counts per app so you know exactly which apps need attention
See [notification settings](/documentation/serverless/observability/slack-notifications) to configure alerts.
* **Redesigned notification dropdown** so you can stay on top of issues without leaving the page you're on
* **Category filtering** lets you cut through noise and focus on the notification types that matter to you
* **Pagination** so you can browse your full notification history without losing your place
* **Mark all as read** to quickly clear your inbox when you've caught up
* **OOM alerts** notify you when a runner runs out of memory, so you can resize before it impacts users
* **Notification badge on app tabs** shows unread counts per app so you know exactly which apps need attention
See [notification settings](/documentation/serverless/observability/slack-notifications) to configure alerts.
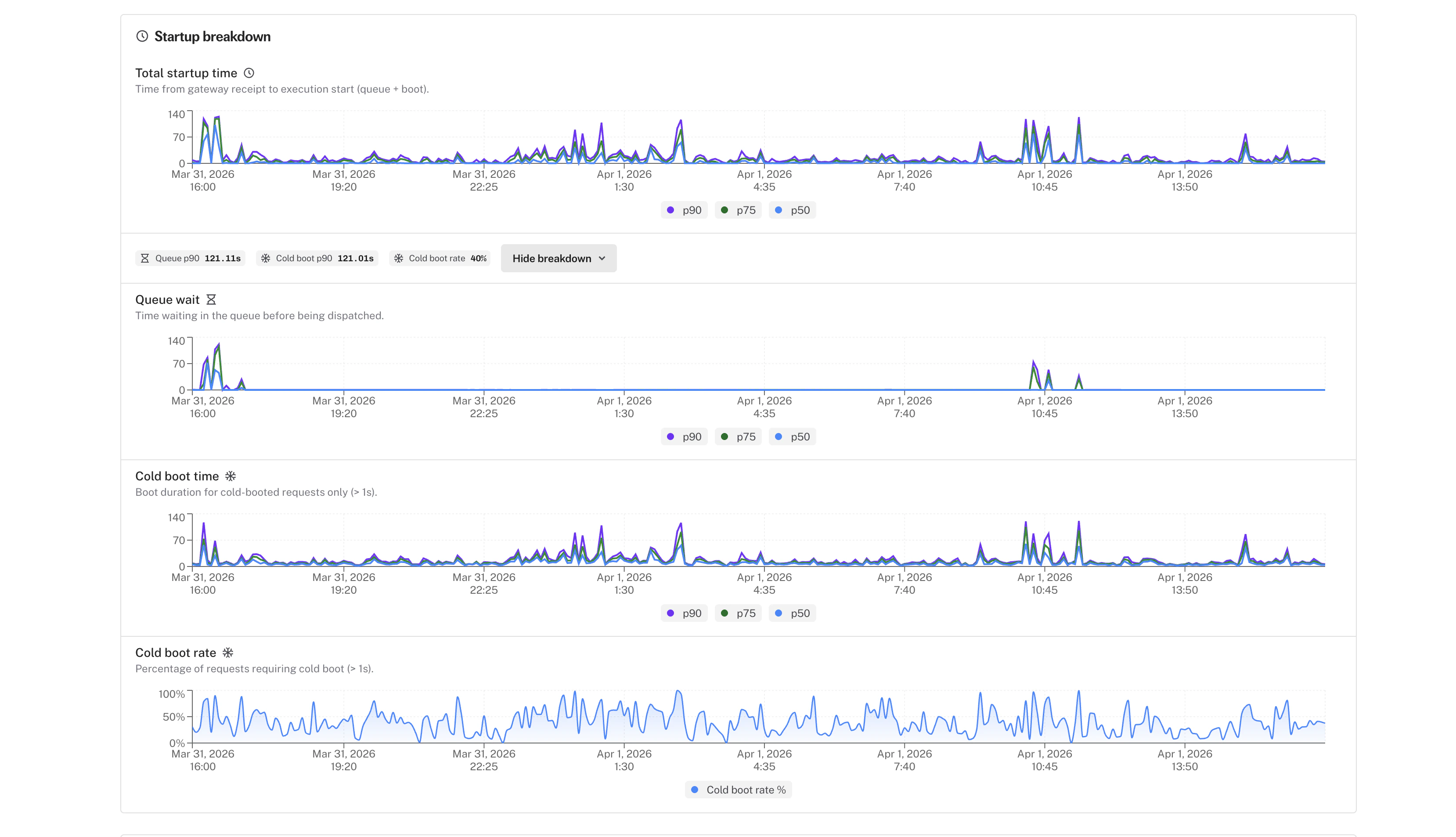 * **Cold start ratio** shows what percentage of requests hit a cold start, so you can measure the impact of your scaling configuration
* **Cold start duration percentiles** (p50, p75, p90, p95) help you understand whether cold starts are a minor delay or a real bottleneck for your users
* **Queue wait percentiles** (p50, p75, p90, p95) reveal how long requests wait before a runner picks them up, helping you decide if you need more concurrency
* A new **startup breakdown card** shows exactly where startup time goes (image pull, setup, etc.) so you know what to optimize
* The [analytics](/documentation/serverless/observability/app-analytics) layout has been redesigned with expandable sections so you can focus on the metrics that matter most
* **Cold start ratio** shows what percentage of requests hit a cold start, so you can measure the impact of your scaling configuration
* **Cold start duration percentiles** (p50, p75, p90, p95) help you understand whether cold starts are a minor delay or a real bottleneck for your users
* **Queue wait percentiles** (p50, p75, p90, p95) reveal how long requests wait before a runner picks them up, helping you decide if you need more concurrency
* A new **startup breakdown card** shows exactly where startup time goes (image pull, setup, etc.) so you know what to optimize
* The [analytics](/documentation/serverless/observability/app-analytics) layout has been redesigned with expandable sections so you can focus on the metrics that matter most
 New charts are available on the [App Analytics](/documentation/serverless/observability/app-analytics) Requests tab:
* **Processed requests per second** chart shows your inference throughput over time
* **Received requests per second** chart shows the inbound request rate
* **Concurrent requests** chart shows how many requests are in-flight simultaneously
New charts are available on the [App Analytics](/documentation/serverless/observability/app-analytics) Requests tab:
* **Processed requests per second** chart shows your inference throughput over time
* **Received requests per second** chart shows the inbound request rate
* **Concurrent requests** chart shows how many requests are in-flight simultaneously
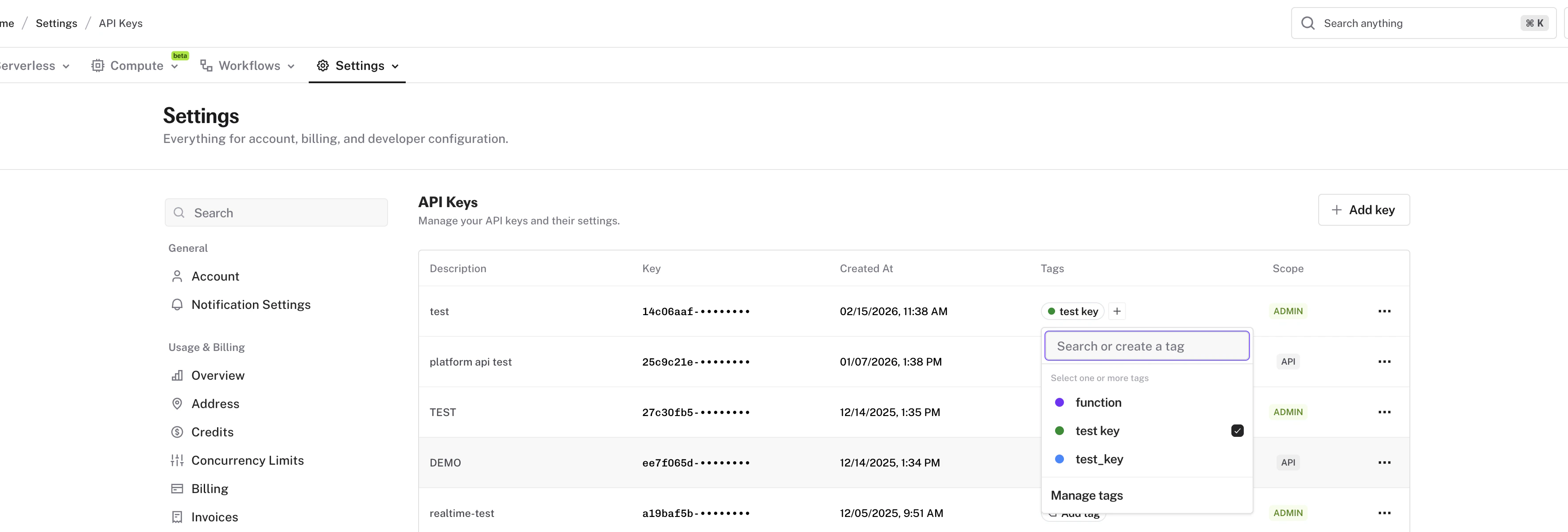 * **Tags on [API keys](/documentation/setting-up/authentication/index)** let you organize keys with the same tagging system used for apps
* **Editable key descriptions** can now be updated directly from the dashboard without recreating the key
* **Tags on [API keys](/documentation/setting-up/authentication/index)** let you organize keys with the same tagging system used for apps
* **Editable key descriptions** can now be updated directly from the dashboard without recreating the key
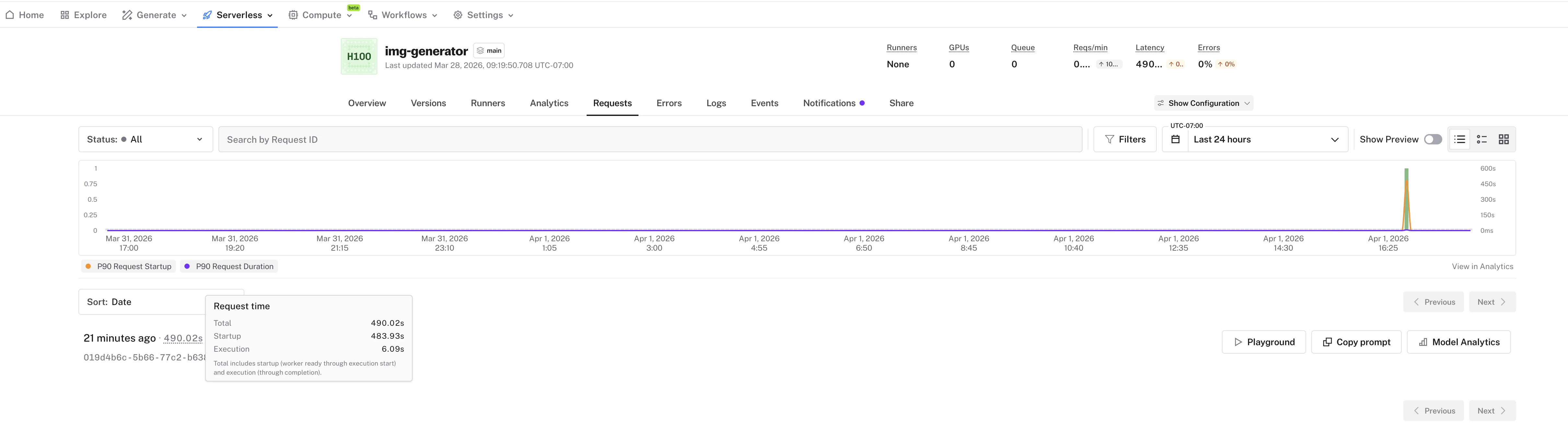 * Request duration in the [requests list](/serverless/deployment-operations/monitor-performance) now shows a **breakdown into startup time and execution time**
* Hover over the duration to see the full timing detail
* Request duration in the [requests list](/serverless/deployment-operations/monitor-performance) now shows a **breakdown into startup time and execution time**
* Hover over the duration to see the full timing detail
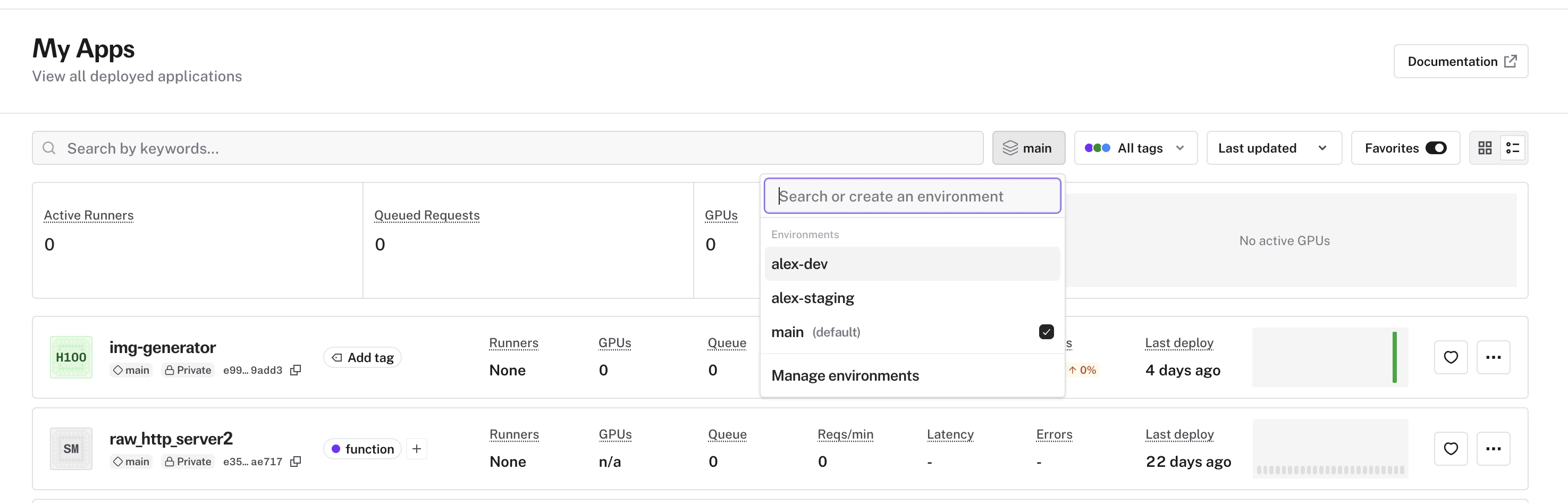 * A new **[environment manager](/serverless/deployment-operations/manage-environments) dialog** lets you create and delete environments in one place
* The environment selector is now **searchable**, replacing the old dropdown
* A new **[environment manager](/serverless/deployment-operations/manage-environments) dialog** lets you create and delete environments in one place
* The environment selector is now **searchable**, replacing the old dropdown
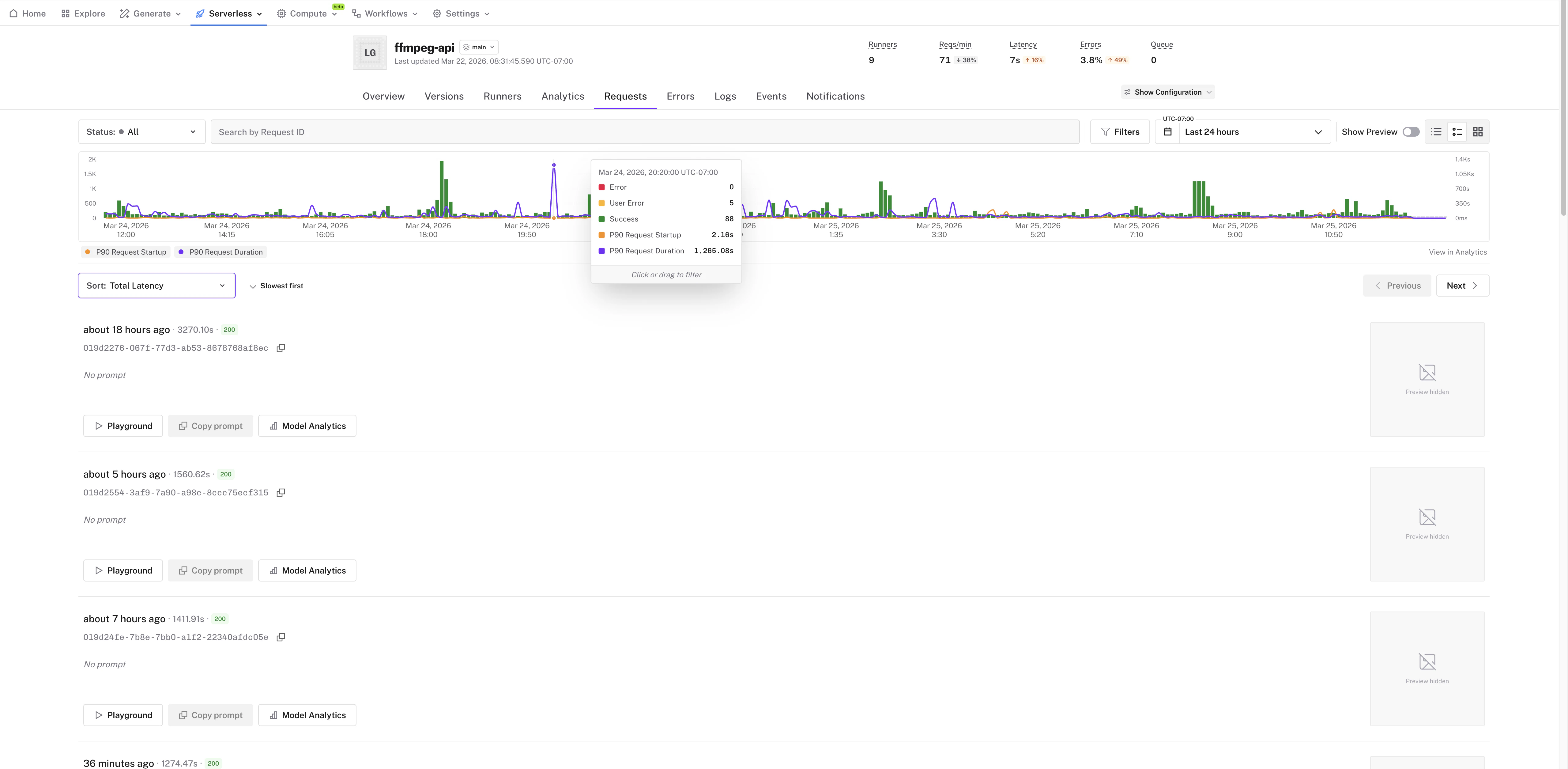 * **Status code and latency charts** — the requests page now shows interactive charts for request status code distribution and p90 latency over time, giving you an instant picture of your app's health
* **Click and drag to filter** — select a time range on any chart to filter the request list below to just that window, making it easy to isolate a spike or incident
* **Sort by cold start, execution time, and latency** — sort the request list by longest cold start duration, execution time, total latency, and more to quickly surface the slowest or most problematic requests
* **Jump to Analytics** — a direct link takes you from the requests page to App Analytics with your current filters pre-applied
* **Status code and latency charts** — the requests page now shows interactive charts for request status code distribution and p90 latency over time, giving you an instant picture of your app's health
* **Click and drag to filter** — select a time range on any chart to filter the request list below to just that window, making it easy to isolate a spike or incident
* **Sort by cold start, execution time, and latency** — sort the request list by longest cold start duration, execution time, total latency, and more to quickly surface the slowest or most problematic requests
* **Jump to Analytics** — a direct link takes you from the requests page to App Analytics with your current filters pre-applied
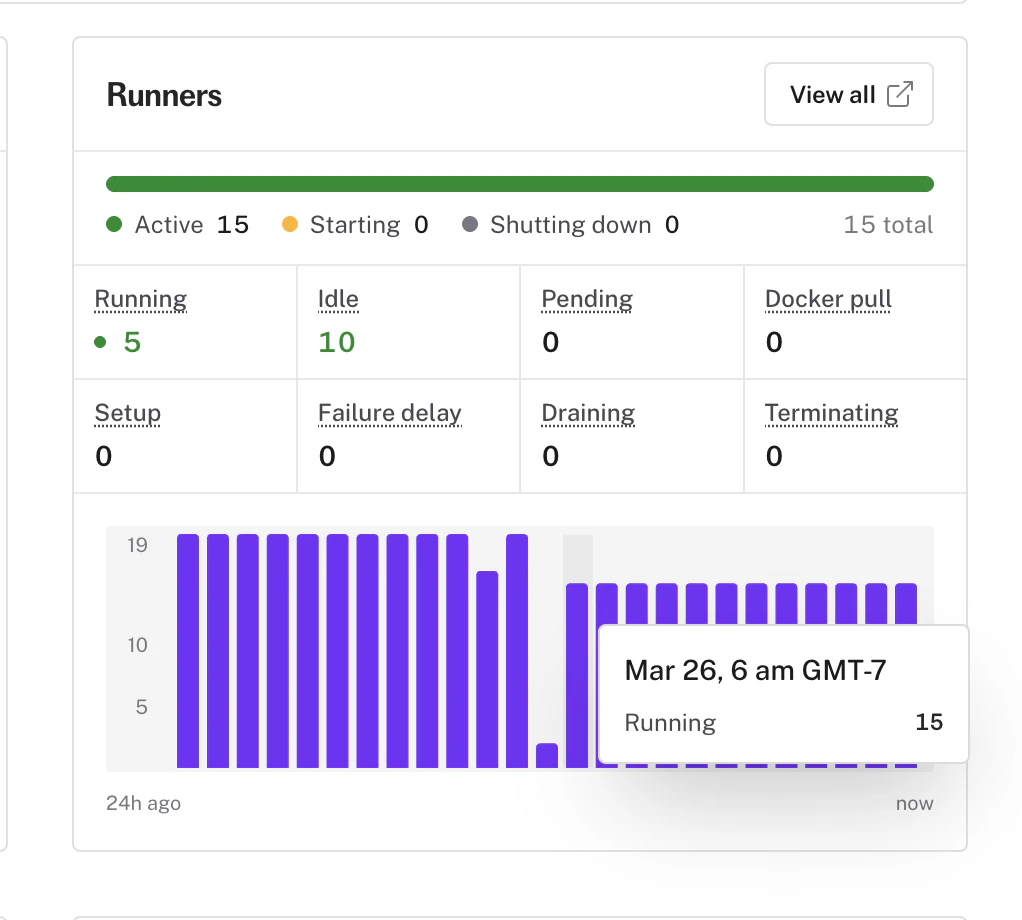 * The app overview page now includes a **runner summary card** showing active runner counts, state breakdowns, and a concurrency trend chart at a glance
* Quickly see how many runners are in each state (running, idle, pending, setup) without navigating to the Runners page
* The app overview page now includes a **runner summary card** showing active runner counts, state breakdowns, and a concurrency trend chart at a glance
* Quickly see how many runners are in each state (running, idle, pending, setup) without navigating to the Runners page
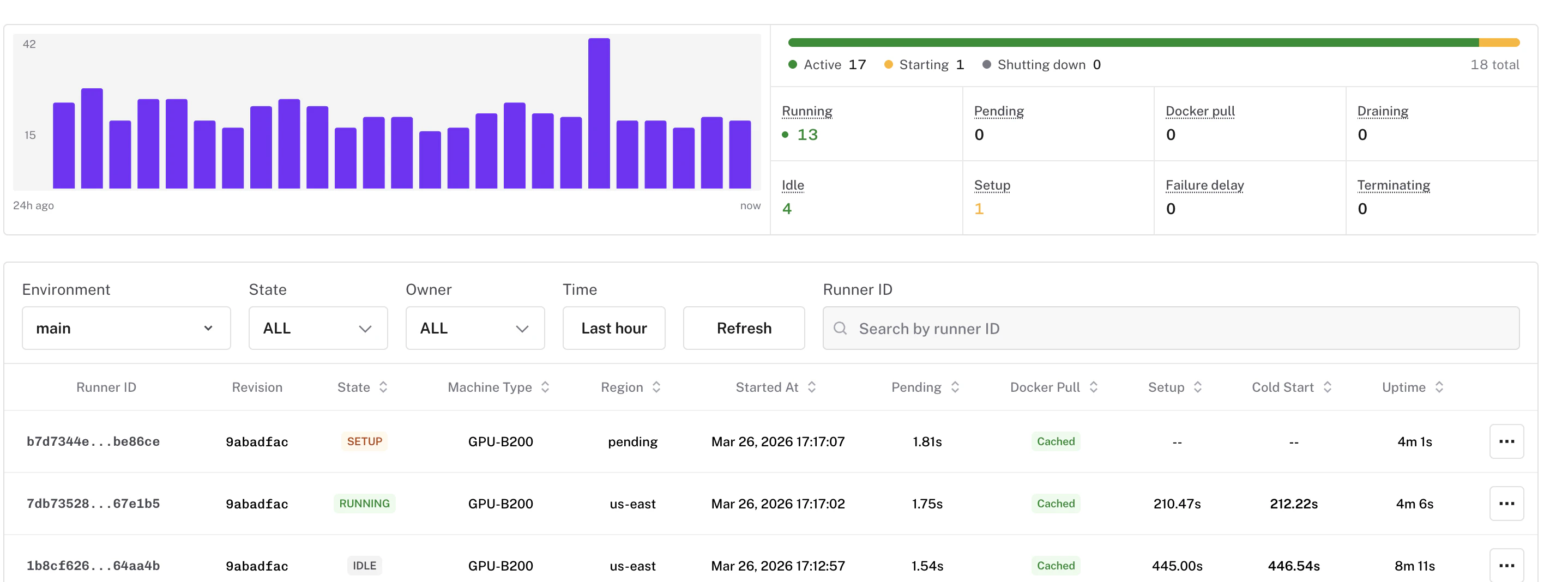 * Search for a specific runner by its ID on the Runners page — useful when you have a runner ID from logs, alerts, or incident reports
* Results display instantly with full runner details, and the Refresh button re-fetches the searched runner
* Search for a specific runner by its ID on the Runners page — useful when you have a runner ID from logs, alerts, or incident reports
* Results display instantly with full runner details, and the Refresh button re-fetches the searched runner
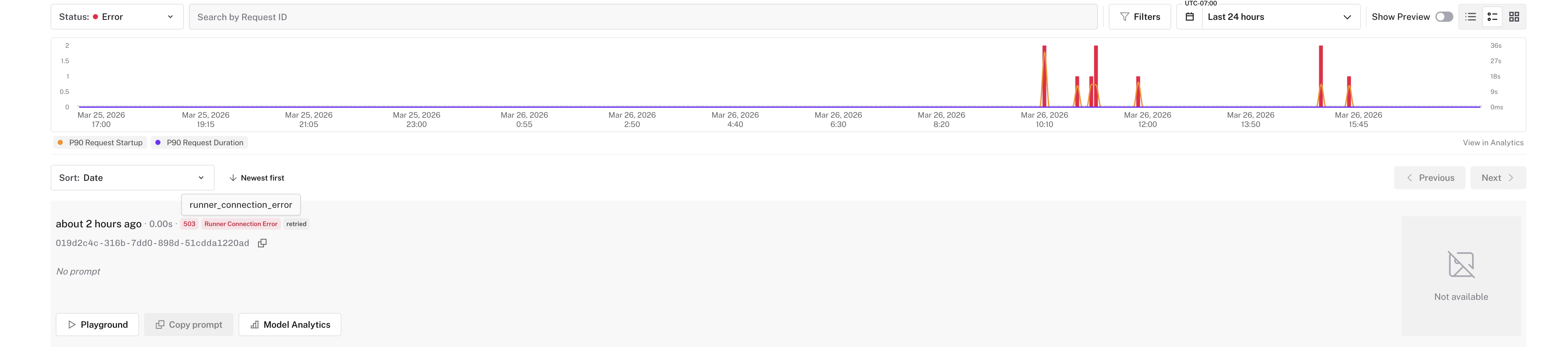 * Failed requests in the dashboard now show the **specific reason** for the failure — not just a status code, but whether it was a `request_timeout`, `runner_disconnected`, `startup_timeout`, `runner_scheduling_failure`, and more
* Instantly understand if a 500 was caused by your code crashing, the runner running out of memory, or a scheduling issue — without digging through logs
* Error types are shown as badges on request rows and in the request detail view, matching the `error_type` field in [API responses](/model-apis/errors#request-error-types)
* Failed requests in the dashboard now show the **specific reason** for the failure — not just a status code, but whether it was a `request_timeout`, `runner_disconnected`, `startup_timeout`, `runner_scheduling_failure`, and more
* Instantly understand if a 500 was caused by your code crashing, the runner running out of memory, or a scheduling issue — without digging through logs
* Error types are shown as badges on request rows and in the request detail view, matching the `error_type` field in [API responses](/model-apis/errors#request-error-types)
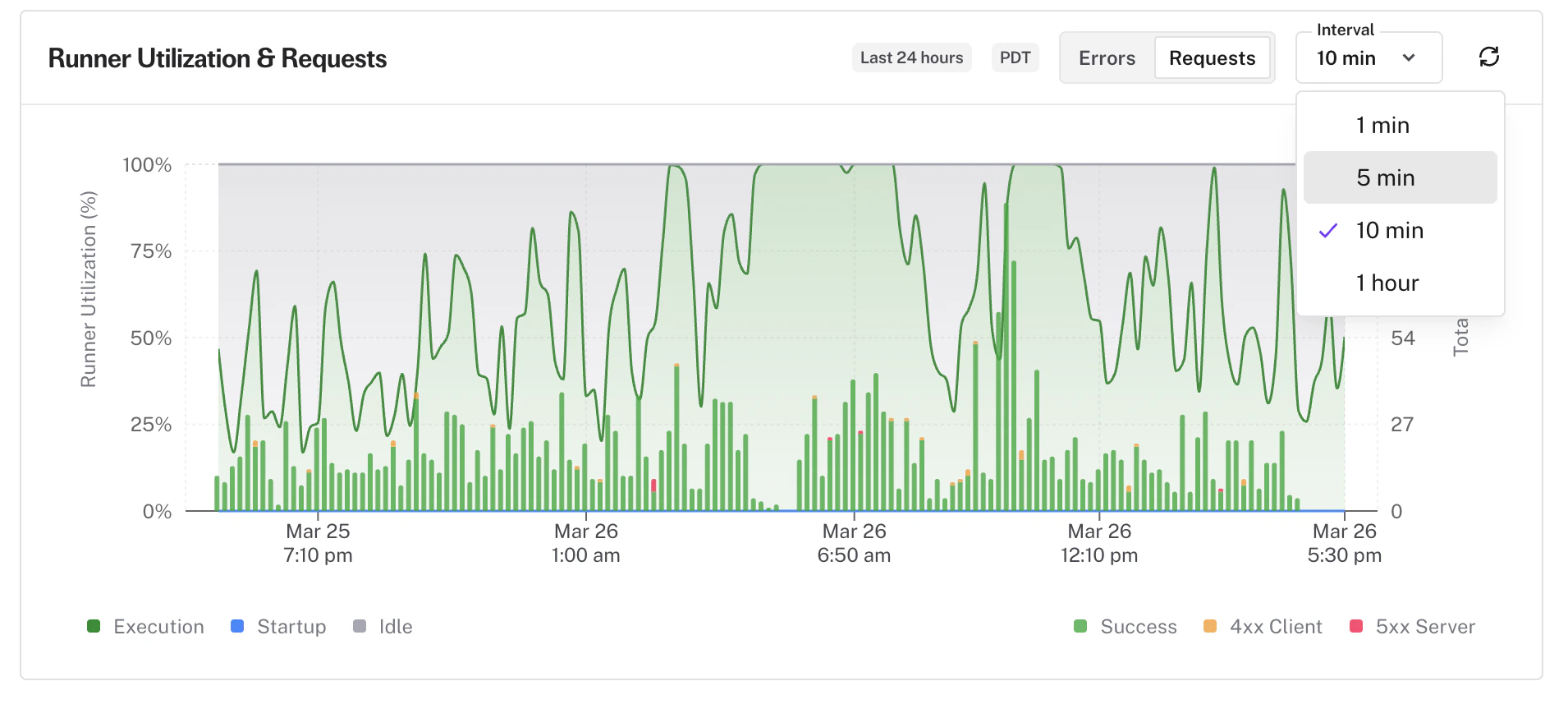 * The app overview chart now includes a **granularity picker** to control the time bucket size — defaults to 10-minute intervals
* Choose finer or coarser intervals to zoom into specific traffic patterns or view broader trends
* The app overview chart now includes a **granularity picker** to control the time bucket size — defaults to 10-minute intervals
* Choose finer or coarser intervals to zoom into specific traffic patterns or view broader trends